









Web Scraping is the technique of automatically collecting data from websites, helping businesses extract information at a speed and scale that manual effort cannot match. This article explains in detail what web scraping is, how it works, popular tools, the role of proxies, and important legal considerations.
What is Web Scraping?
Web Scraping (also known as web harvesting or web data extraction) is the process of using software or scripts to automatically access websites and extract structured data from their HTML source code. Instead of manually copying each piece of information, web scraping allows you to collect millions of data points in just minutes.
Difference Between Web Scraping and Web Crawling
Many people confuse these two concepts:
-
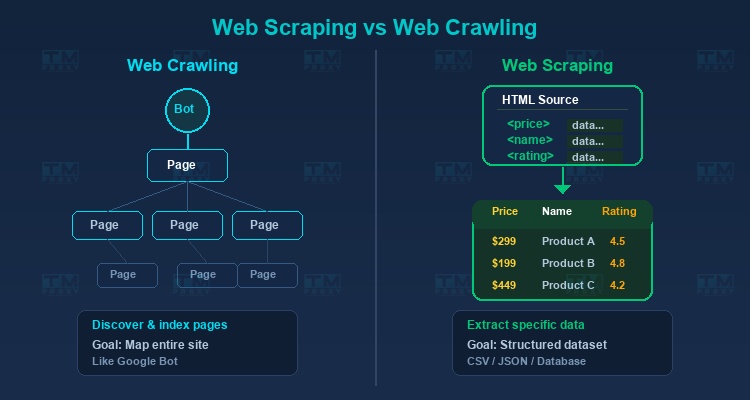
Web Crawling is the process of browsing and indexing web pages, similar to how Google Bot works. Its primary goal is to discover and map website structures.
-
Web Scraping focuses on extracting specific data from known pages. For example: getting product prices, customer reviews, or contact information.
In practice, a data collection project often combines both: crawling to find the necessary URLs, then scraping to extract data from each URL.
High-Speed Proxy - Ready to Try?
ALGO Proxy offers residential, datacenter & 4G proxies in 195+ countries
How Does Web Scraping Work?
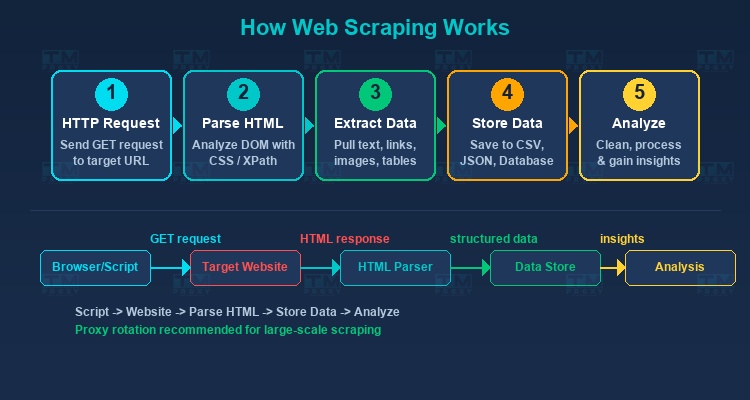
The basic web scraping workflow involves the following steps:
Send HTTP Request
The script sends an HTTP request (usually GET) to the target URL, just like when your browser accesses a web page. The server responds with the page's HTML code.
Parse HTML
After receiving the HTML, the scraping tool analyzes the DOM (Document Object Model) structure to identify where the target data is located. Common methods include:
- CSS Selectors: Select elements based on class, id, or HTML structure.
- XPath: A powerful query language for XML/HTML that allows precise navigation within the DOM structure.
- Regular Expressions: Search for specific text patterns in HTML.
Extract Data
Data is extracted from the identified HTML elements — this can be text, attributes (href, src), tables, or any content displayed on the page.
Store Data
Extracted data is saved in structured formats like CSV, JSON, Excel, or databases (MySQL, PostgreSQL, MongoDB).
Process and Analyze
Raw data is cleaned, normalized, and analyzed to derive valuable business insights.
Popular Web Scraping Tools
Programming Libraries
-
Beautiful Soup (Python): A simple, easy-to-use HTML/XML parsing library. Suitable for small to medium scraping projects.
-
Scrapy (Python): A powerful and comprehensive scraping framework. Supports asynchronous processing, data pipelines, and middleware. Ideal for large-scale projects.
-
Puppeteer (Node.js): A library for controlling headless Chrome/Chromium browsers. Excellent for handling websites that use JavaScript rendering.
-
Playwright (Multi-language): Similar to Puppeteer but supports multiple browsers (Chrome, Firefox, Safari) and multiple programming languages.
-
Selenium: A browser automation tool that allows interaction with websites like a real user (clicking, scrolling, filling forms).
No-Code Platforms
-
Octoparse: An intuitive drag-and-drop interface requiring no coding. Perfect for users without programming experience.
-
ParseHub: Similar to Octoparse, supports scraping complex websites with JavaScript.
-
Apify: A cloud-based platform providing ready-made actors (scripts) for many popular websites.
Challenges in Web Scraping
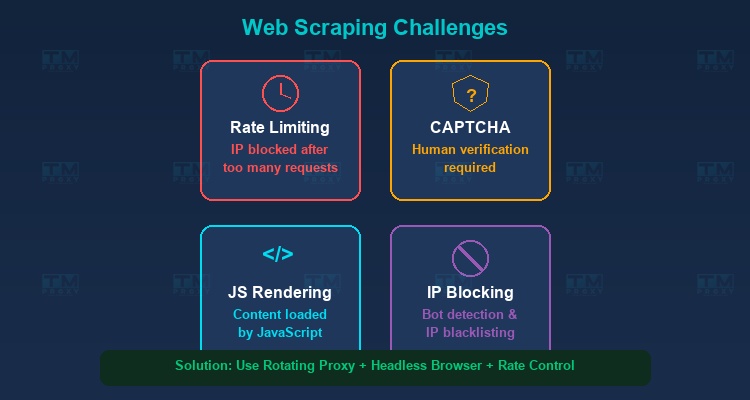
Anti-Scraping Mechanisms
Websites increasingly implement measures to block scraping bots:
- Rate Limiting: Restricts the number of requests from a single IP within a given timeframe.
- CAPTCHA: Requires verification that the user is human.
- IP Blocking: Blocks IPs that send too many requests or exhibit abnormal behavior.
- User-Agent Detection: Detects and blocks requests that don't come from real browsers.
- Honeypot Traps: Hidden links that only bots would access, used to identify scrapers.
JavaScript Rendering
Many modern websites use JavaScript to render content (Single Page Applications - SPA). This means the initial HTML doesn't contain the data — data is only loaded after JavaScript executes. The solution is to use headless browsers like Puppeteer or Playwright.
HTML Structure Changes
Websites frequently update their interfaces, causing scraper selectors to break. Scrapers need to be designed flexibly with monitoring systems to detect errors early.
Large-Scale Data Processing
Collecting millions of pages requires systems capable of parallel processing, queue management, and efficient storage.
The Role of Proxies in Web Scraping
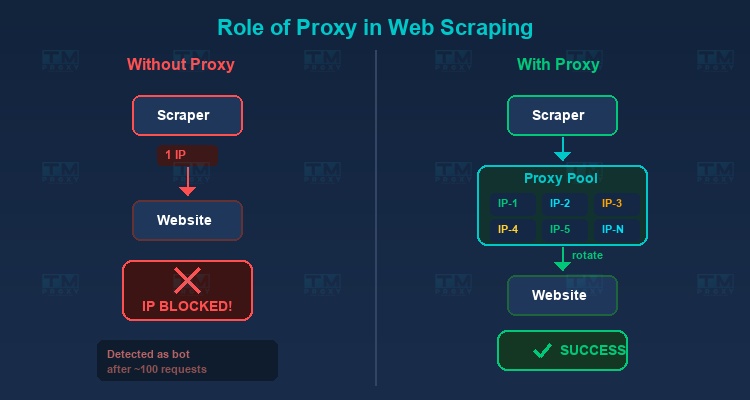
Proxies are an essential component of any large-scale web scraping project. Here's why:
Avoiding IP Blocks
When sending thousands of requests from the same IP, the website will quickly detect and block you. Proxies allow you to rotate IPs continuously, distributing requests across many different IP addresses.
Bypassing Geo-Restrictions
Some websites display different content depending on geographic location. Proxies from different countries let you access content from any region.
Increasing Collection Speed
Using multiple proxies simultaneously allows parallel requests, significantly increasing scraping speed without exceeding the rate limit for each individual IP.
Best Proxy Types for Scraping
-
Residential Proxy: The best choice for scraping. Real ISP IPs that are very hard to detect as bots. Ideal for websites with strong anti-scraping measures.
-
Datacenter Proxy: High speed, lower cost. Suitable for scraping websites with less protection or low rate limits.
-
Rotating Proxy: Automatically changes IP after each request or after a set time period. Perfect for large-scale scraping.
| Proxy Type | Success Rate | Avg Speed | IPs Blocked | Cost/10K pages |
|---|---|---|---|---|
| Residential | 98.5% | 1.2s/page | 0.3% | $$ |
| Datacenter | 72% | 0.4s/page | 28% | $ |
| Rotating Residential | 99.2% | 1.5s/page | 0.1% | $$$ |
Rotating residential proxy achieved the highest success rate (99.2%) with virtually no IP blocks. Datacenter proxy was faster but had 28% of requests blocked.
TMProxy offers all these proxy types with over 10 million IPs from 200+ countries and automatic IP rotation — the perfect solution for professional web scraping.
Real-World Applications of Web Scraping
Price Monitoring
E-commerce businesses use scraping to track competitor product prices in real-time, allowing them to adjust their pricing strategies accordingly.
Market Research
Collecting product reviews, social media comments, and search trends to understand customer needs and sentiment.
HR Tech / Recruitment
Gathering job listings from employment websites to analyze labor market trends, salary levels, and in-demand skills.
Real Estate
Collecting property listings, prices, and area information from real estate websites for market analysis.
SEO and Digital Marketing
Tracking keyword rankings, analyzing competitor backlinks, and collecting SERP (Search Engine Results Page) data.
Legal Considerations for Web Scraping
Web scraping is not always legal. You should be aware of:
-
Terms of Service (ToS): Many websites prohibit scraping in their terms of use. Violations can lead to legal consequences.
-
Robots.txt: This file specifies which parts of a website allow or disallow bot access. You should respect the robots.txt file.
-
Personal Data: Collecting personal data must comply with data protection regulations like GDPR (Europe) and CCPA (California).
-
Copyright: Copyrighted content should not be copied or redistributed without permission.
Best Practices for Effective Web Scraping
To build a sustainable and professional scraping system, follow these key principles:
Respect robots.txt
Always check and follow the target website's robots.txt file before scraping. This file specifies which URLs bots are allowed or disallowed to access. While robots.txt is not legally binding in all jurisdictions, respecting it demonstrates professional ethics and reduces the risk of being blocked.
Implement Rate Limiting
Don't send requests too quickly — this can overwhelm the target server and get your IP blocked immediately. Set a minimum delay of 1-3 seconds between requests, or adjust according to the site's allowed rate.
Use Rotating Proxies
Continuous IP rotation is critical for large-scale scraping. A diverse proxy pool with IPs from multiple countries and ISPs helps distribute requests and avoid detection. TMProxy offers over 10 million residential IPs with automatic rotation, ideal for any scraping project.
Simulate Real User-Agent and Headers
Send requests with headers that mimic real browsers: User-Agent, Accept, Accept-Language, Referer. Rotate User-Agents between requests to avoid fingerprint-based detection. Use an updated list of User-Agents from popular browsers.
Handle Errors with Exponential Backoff
When encountering errors (HTTP 429, 503, timeouts), don't retry immediately. Use exponential backoff — wait 1s, then 2s, 4s, 8s... Set a maximum retry limit (usually 3-5 attempts) to avoid infinite loops. Log errors for analysis and scraper improvement.
Store Raw HTML Before Parsing
Always save the raw HTML of pages to storage (files or database) before extracting data. This allows you to re-parse data when extraction logic changes without re-scraping, saving significant time and bandwidth.
Set Up Monitoring and Alerts
Establish a monitoring system to track: request success rates, scraping speed, number of blocked IPs, and data quality. Automatic alerts when error rates exceed thresholds help detect and resolve issues quickly.
Web Scraping Code Example with Python
Here's a simple example using Beautiful Soup to scrape product titles and prices from a website:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/products"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
# Use proxy to avoid blocking
proxies = {"http": "http://user:pass@proxy.tmproxy.com:8080",
"https": "http://user:pass@proxy.tmproxy.com:8080"}
response = requests.get(url, headers=headers, proxies=proxies, timeout=30)
soup = BeautifulSoup(response.text, "html.parser")
products = soup.select(".product-item")
for product in products:
name = product.select_one(".product-name").text.strip()
price = product.select_one(".product-price").text.strip()
print(f"{name}: {price}")
This example demonstrates key best practices: using User-Agent headers, proxies, timeouts, and CSS selectors for structured data extraction.
Web Scraping Trends
AI-Powered Scraping
Artificial intelligence is transforming how scraping works. AI tools can automatically identify page structures, adapt when layouts change, and extract data without manually written selectors. Machine learning helps scrapers "learn" from HTML patterns and self-adjust when websites update.
Headless Browsers as the Standard
With the rise of Single Page Applications (SPA) and JavaScript-heavy websites, headless browsers like Puppeteer and Playwright have become the default tool rather than just a fallback. Modern websites require JavaScript execution to render content, making simple HTTP requests insufficient.
Increasingly Sophisticated Anti-Bot Measures
Cloudflare, Akamai, and other CDNs continuously improve their bot detection capabilities. New techniques include: mouse and keyboard behavior analysis, TLS fingerprinting, and headless browser detection through JavaScript APIs. This requires scrapers to become increasingly sophisticated.
Growth of Scraping-as-a-Service
Many businesses are shifting to external scraping services instead of building their own infrastructure. Platforms like Apify, ScrapingBee, and Bright Data offer simple APIs that handle proxy rotation, CAPTCHA solving, and browser rendering — letting businesses focus on data analysis rather than infrastructure management.
Ethical and Compliant Scraping
There is a growing trend toward ethical practices and legal compliance in the scraping community. Standards and best practices are becoming more clearly established. Businesses invest in compliance, respect ToS and personal data regulations. This helps the web scraping industry develop sustainably and gain wider acceptance.
Conclusion: Web Scraping is a powerful technique that helps businesses efficiently collect and leverage web data. For successful large-scale implementation, you need a reliable proxy system, the right scraping tools, and solid legal knowledge. With the right combination of tools and strategy, web scraping can deliver tremendous value for your business.