









Proxies are a critical tool for AI data collection: bypassing rate limiting, collecting multi-country data, and scaling pipelines to millions of data points. This article provides a detailed guide on choosing the right proxy for each type of AI workload.
AI is Hungry for Data — and Proxy is the Answer
High-Speed Proxy - Ready to Try?
ALGO Proxy offers residential, datacenter & 4G proxies in 195+ countries
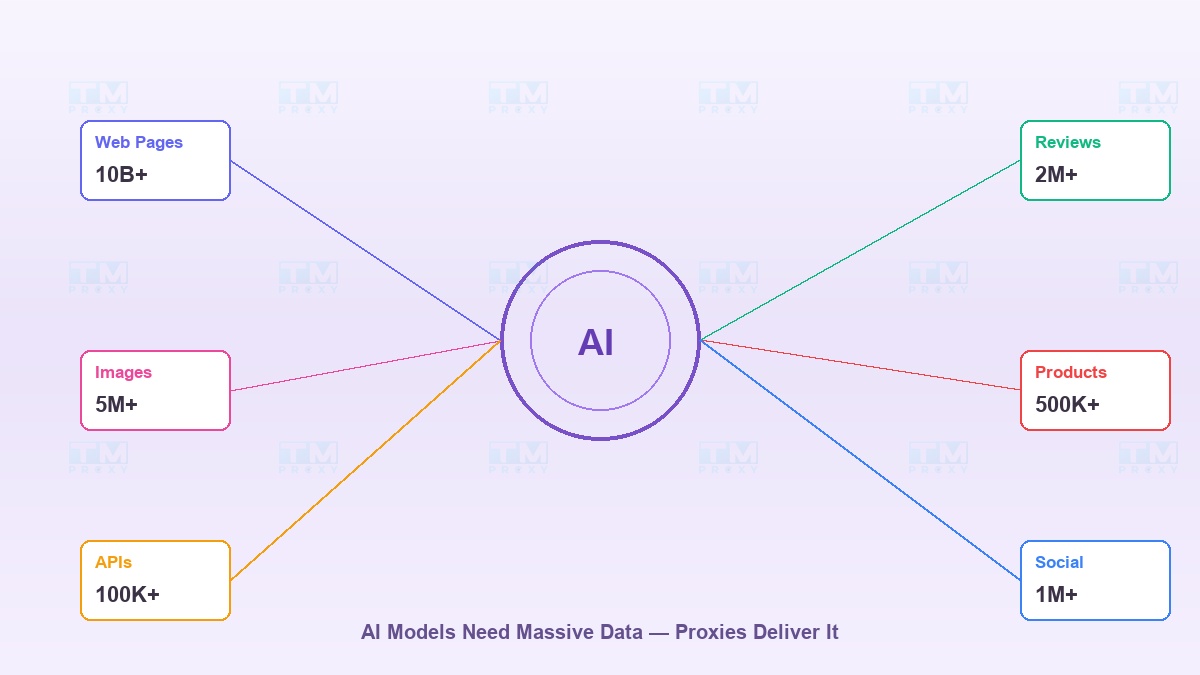
What does a great AI model need? Data. A lot of data.
GPT was trained on billions of web pages. Image recognition models need millions of photos. Recommendation engines need product data from hundreds of e-commerce platforms. All this data lives on the internet — but getting it is a completely different problem.
The issue: websites don't want you crawling their data. They set rate limits, block IPs, require CAPTCHAs. And that's exactly why proxies have become an indispensable tool in the AI ecosystem.
In this article, we'll dive deep into the role of proxies at every stage of AI development — from collecting training data to deployment and monitoring.
The Biggest Challenges in Collecting Data for AI

API Rate Limiting
OpenAI limits 60 requests/minute. Google Search API gives 100 free queries/day. Twitter API allows only 300 requests/15 minutes. When you need millions of data points, these limits become massive barriers.
Solution: A proxy pool distributes requests across multiple IPs. 1 IP = 60 req/min → 100 IPs = 6,000 req/min. Simple and effective.
Geo-Varying Data
Google Search returns different results in the US, Japan, and Vietnam. Amazon displays different prices and products by country. If your AI model needs to understand multicultural context, you must collect data from multiple countries.
Solution: Proxies in 100+ countries let you "sit in one country but see the internet like someone in the US or Japan."
Massive Data Scale
Training an LLM requires terabytes of text data. Computer Vision needs millions of images. At 1 request/second from 1 IP, you'd need months to collect enough. With 1,000 proxies running in parallel, that drops to a few days.
The Right Proxy for Each AI Workload
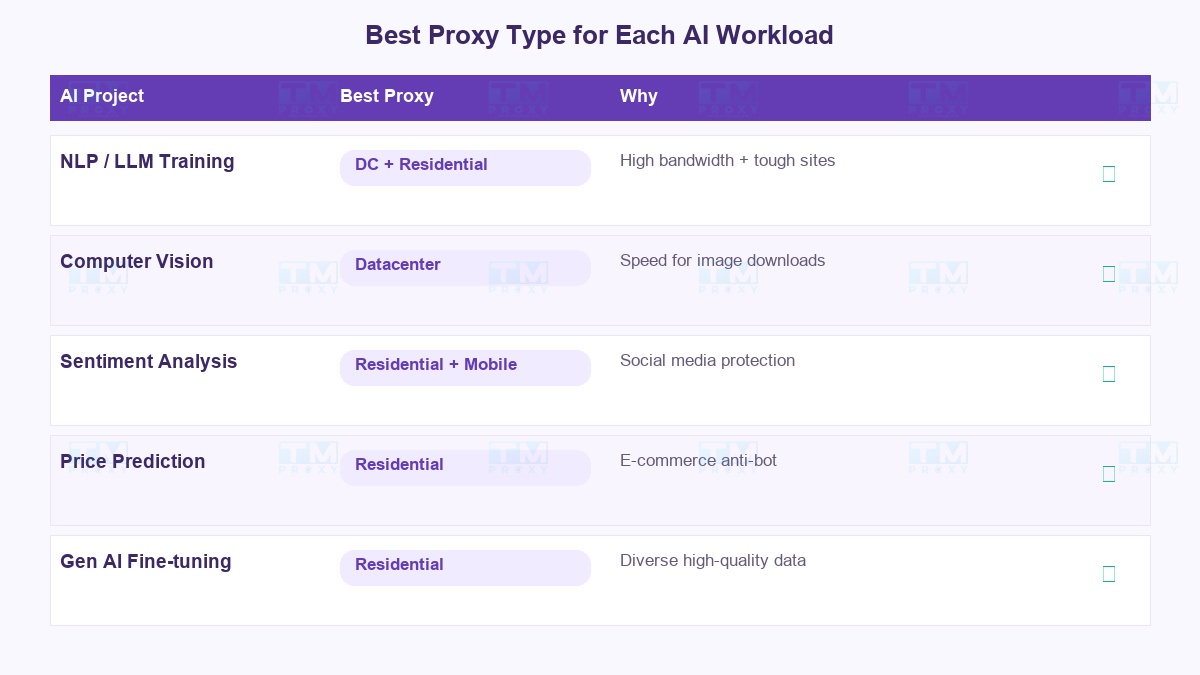
Each type of AI project needs a different proxy. There's no "one-size-fits-all":
| AI Project Type | Best Proxy | Reason |
|---|---|---|
| NLP / LLM Training | Datacenter + Residential | Needs high bandwidth for text data, residential for tough sites |
| Computer Vision | Datacenter | Image downloading needs speed, less blocking since images are usually public |
| Sentiment Analysis | Residential + Mobile | Social media has strict protection, needs trustworthy IPs |
| Price Prediction | Residential | E-commerce sites have strong anti-bot systems |
| Generative AI Fine-tuning | Residential | Needs high-quality data from diverse sources |
| Proxy Type | Success Rate | Speed (req/s) | Cost/1M Requests | Best For |
|---|---|---|---|---|
| Datacenter | 62% | 500+ | $ | APIs, forums, blogs |
| Residential | 94% | 50-100 | $$$ | E-commerce, social media |
| Mobile | 98% | 20-50 | $$$$$ | Heavily protected social media |
Residential proxy achieved the highest success rate for most AI data sources (94%). Datacenter proxy is best for lightly protected sources at the lowest cost.
Datacenter Proxy works when: you need high speed, large bandwidth, and the target website has light protection. Lowest cost, ideal for high-volume API calls.
Residential Proxy works when: target websites have anti-bot systems (Google, Amazon, social media). Real IPs from ISPs, high success rate. The safest choice for most AI projects.
Mobile Proxy works when: collecting data from mobile apps or social media with strict protection. Most expensive but almost never blocked.
AI Data Collection Pipeline: From Idea to Model
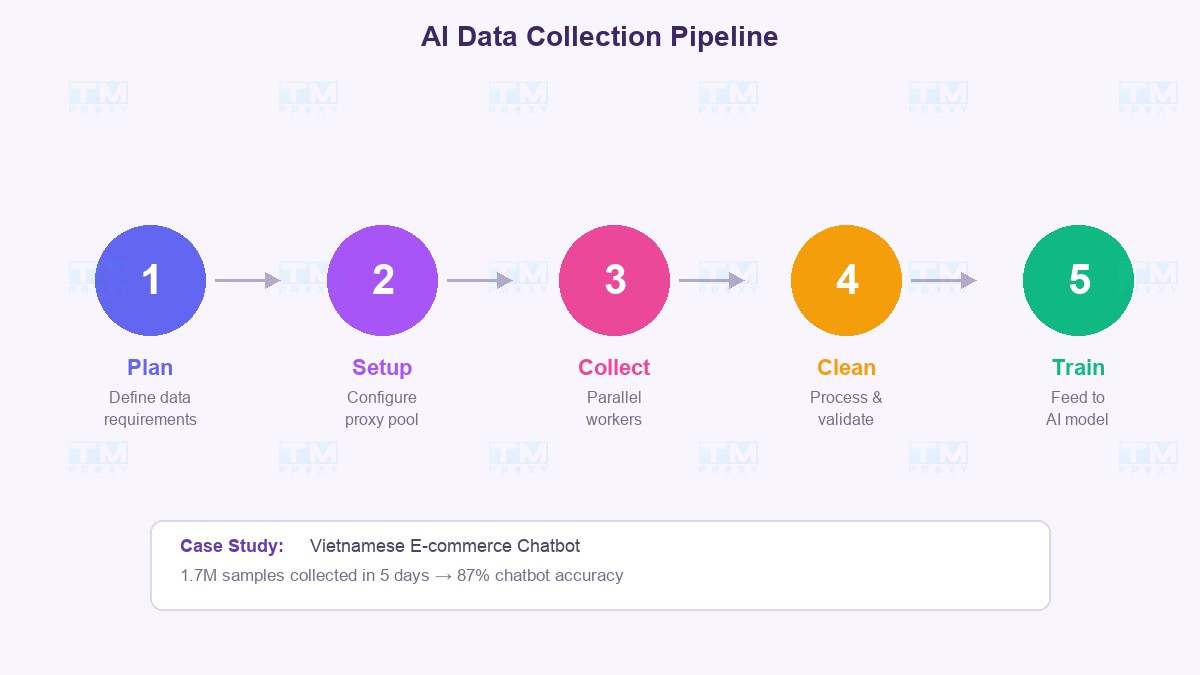
Here's the real-world workflow that professional AI teams use:
Phase 1 → Planning Define clearly: How much data? From which sources? What frequency? Example: "Need 1 million Vietnamese product reviews from 5 e-commerce platforms, updated daily."
Phase 2 → Proxy Infrastructure Setup Choose provider, configure proxy pool, test success rates on target websites. Start with 100 IPs, scale up gradually.
Phase 3 → Parallel Collection Run multiple workers simultaneously, each using its own proxy. Pipeline: Request → Parse → Validate → Store. Collection speed scales linearly with proxy count.
Phase 4 → Processing and Cleaning Remove duplicates, filter noise, normalize formats. This step runs in parallel with collection — no need to wait for collection to finish.
Phase 5 → Training and Evaluation Feed data into the model, evaluate results. If quality isn't sufficient → go back to Phase 1 with new data sources.
Case Study: Collecting Data for a Vietnamese Chatbot
A real project: Building a customer support chatbot for Vietnamese e-commerce.
Data Requirements:
- 500K question-answer pairs from support forums
- 200K product descriptions from Shopee, Lazada, Tiki
- 1M product reviews with ratings
Proxy Solution:
- Vietnamese residential proxies for Shopee, Lazada (strong anti-bot)
- Datacenter proxies for forums, blogs (light protection)
- Rotation: change IP every 5 requests, 3-5 second delay
Results:
- Collection completed in 5 days instead of an estimated 2 months without proxies
- Success rate: 94% (residential) and 78% (datacenter)
- Chatbot achieved 87% accuracy after training on this dataset
Important Notes When Collecting Data for AI
Collecting data for AI isn't just a technical problem. Keep in mind:
- GDPR & Privacy: Personal data in the EU requires strict compliance. Anonymize data before using it for training.
- robots.txt: Always check and respect it. Beyond legal issues, many anti-bots use it as a honeypot.
- Terms of Service: Each website has its own ToS. Read carefully before large-scale scraping.
- Data Quality > Quantity: 100K high-quality samples are better than 1M noisy ones. Invest in data cleaning.
- Continuous Monitoring: Websites change structure frequently. Monitor your pipeline 24/7.
TMProxy for AI Projects
TMProxy understands that AI workloads are fundamentally different from regular browsing. We provide:
- For data collection: Pool of millions of residential IPs across 100+ countries. Unlimited bandwidth. Easy API integration into Python/Node.js pipelines.
- For API access: High-speed, low-latency datacenter proxies. Sticky session support when you need to maintain context.
- For teams: Usage management dashboard, per-project permissions, transparent billing.
Conclusion: In the AI race, data is fuel and proxies are the pipeline that delivers it. Investing in quality proxy infrastructure isn't a cost — it's a competitive advantage. Let TMProxy help you build better AI, faster.