









Web Scraping là kỹ thuật tự động thu thập dữ liệu từ các trang web, giúp doanh nghiệp trích xuất thông tin với tốc độ và quy mô mà con người không thể thực hiện thủ công. Bài viết giải thích chi tiết Web Scraping là gì, cách hoạt động, công cụ phổ biến, vai trò của proxy và lưu ý pháp lý quan trọng.
Web Scraping là gì?
Web Scraping (còn gọi là web harvesting hoặc web data extraction) là quá trình sử dụng phần mềm hoặc script để tự động truy cập các trang web và trích xuất dữ liệu có cấu trúc từ mã HTML của trang. Thay vì sao chép thủ công từng thông tin, web scraping cho phép bạn thu thập hàng triệu điểm dữ liệu chỉ trong vài phút.
Sự khác biệt giữa Web Scraping và Web Crawling
Nhiều người nhầm lẫn hai khái niệm này:
-
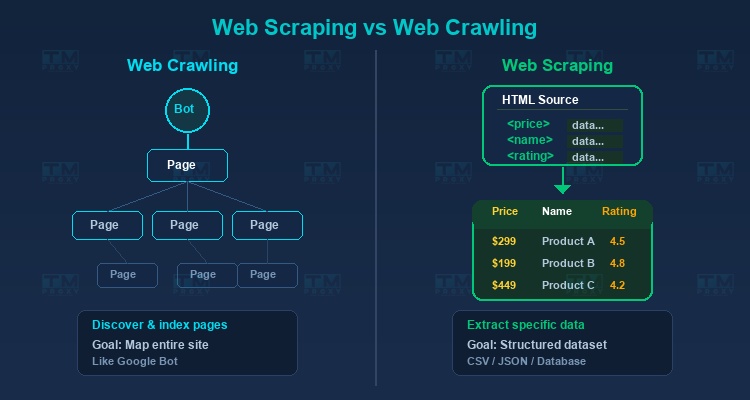
Web Crawling là quá trình duyệt và lập chỉ mục các trang web, tương tự như cách Google Bot hoạt động. Mục tiêu chính là khám phá và lập bản đồ cấu trúc website.
-
Web Scraping tập trung vào việc trích xuất dữ liệu cụ thể từ các trang đã biết. Ví dụ: lấy giá sản phẩm, đánh giá khách hàng hoặc thông tin liên hệ.
Trong thực tế, một dự án thu thập dữ liệu thường kết hợp cả hai: crawling để tìm các URL cần thiết, sau đó scraping để trích xuất dữ liệu từ từng URL.
Proxy tốc độ cao – Sẵn sàng dùng thử?
ALGO Proxy cung cấp proxy residential, datacenter và 4G tại 195+ quốc gia
Web Scraping hoạt động như thế nào?
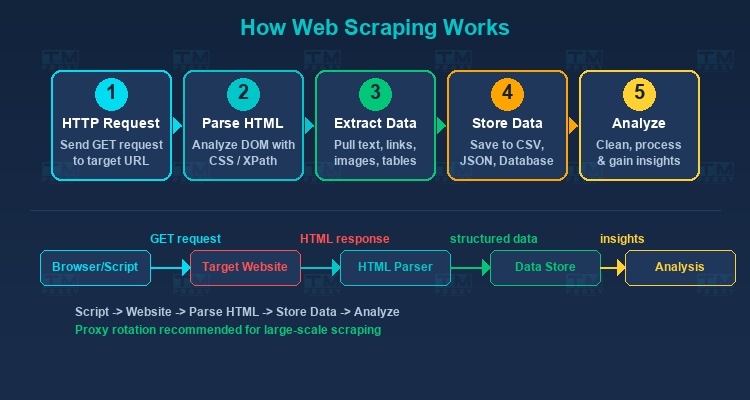
Quy trình cơ bản của web scraping bao gồm các bước sau:
Gửi HTTP Request
Script gửi yêu cầu HTTP (thường là GET) đến URL mục tiêu, giống như khi trình duyệt của bạn truy cập một trang web. Server phản hồi với mã HTML của trang.
Phân tích HTML (Parsing)
Sau khi nhận được HTML, công cụ scraping sẽ phân tích cấu trúc DOM (Document Object Model) để xác định vị trí của dữ liệu cần thu thập. Các phương pháp phổ biến:
- CSS Selectors: Chọn phần tử dựa trên class, id hoặc cấu trúc HTML.
- XPath: Ngôn ngữ truy vấn mạnh mẽ cho XML/HTML, cho phép điều hướng chính xác trong cấu trúc DOM.
- Regular Expressions: Tìm kiếm mẫu văn bản cụ thể trong HTML.
Trích xuất dữ liệu
Dữ liệu được trích xuất từ các phần tử HTML đã xác định — có thể là text, thuộc tính (href, src), bảng biểu hoặc bất kỳ nội dung nào hiển thị trên trang.
Lưu trữ dữ liệu
Dữ liệu đã trích xuất được lưu vào định dạng có cấu trúc như CSV, JSON, Excel hoặc cơ sở dữ liệu (MySQL, PostgreSQL, MongoDB).
Xử lý và phân tích
Dữ liệu thô được làm sạch, chuẩn hóa và phân tích để rút ra insights có giá trị cho doanh nghiệp.
Các công cụ Web Scraping phổ biến
Thư viện lập trình
-
Beautiful Soup (Python): Thư viện phân tích HTML/XML đơn giản, dễ sử dụng. Phù hợp cho các dự án scraping nhỏ và vừa.
-
Scrapy (Python): Framework scraping mạnh mẽ và hoàn chỉnh. Hỗ trợ xử lý bất đồng bộ, pipeline dữ liệu và middleware. Phù hợp cho dự án quy mô lớn.
-
Puppeteer (Node.js): Thư viện điều khiển trình duyệt headless Chrome/Chromium. Giải quyết tốt các trang web sử dụng JavaScript rendering.
-
Playwright (Multi-language): Tương tự Puppeteer nhưng hỗ trợ nhiều trình duyệt (Chrome, Firefox, Safari) và nhiều ngôn ngữ lập trình.
-
Selenium: Công cụ tự động hóa trình duyệt, cho phép tương tác với trang web như người dùng thật (click, scroll, điền form).
Nền tảng No-Code
-
Octoparse: Giao diện kéo thả trực quan, không cần viết code. Phù hợp cho người không có kinh nghiệm lập trình.
-
ParseHub: Tương tự Octoparse, hỗ trợ scraping các trang web phức tạp với JavaScript.
-
Apify: Nền tảng cloud-based cung cấp các actor (script) sẵn có cho nhiều trang web phổ biến.
Thách thức trong Web Scraping
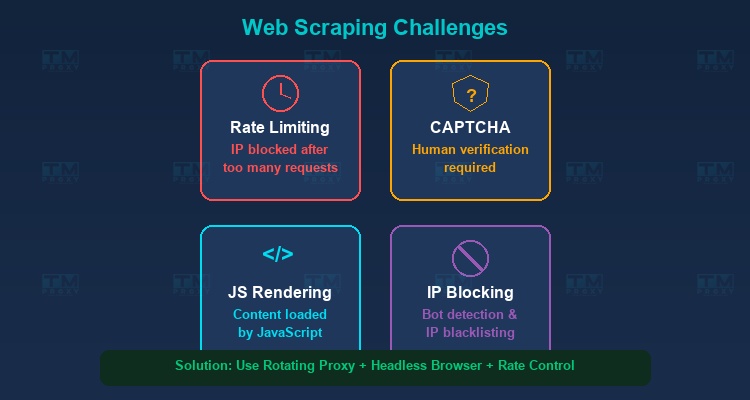
Cơ chế chống scraping
Các trang web ngày càng triển khai nhiều biện pháp để chặn bot scraping:
- Rate Limiting: Giới hạn số lượng request từ một IP trong khoảng thời gian nhất định.
- CAPTCHA: Yêu cầu xác minh người dùng là con người.
- IP Blocking: Chặn các IP gửi quá nhiều request hoặc có hành vi bất thường.
- User-Agent Detection: Phát hiện và chặn request không đến từ trình duyệt thật.
- Honeypot Traps: Các liên kết ẩn mà chỉ bot mới truy cập, dùng để phát hiện scraper.
JavaScript Rendering
Nhiều trang web hiện đại sử dụng JavaScript để render nội dung (Single Page Applications - SPA). Điều này có nghĩa là HTML ban đầu không chứa dữ liệu — dữ liệu chỉ được tải sau khi JavaScript thực thi. Giải pháp là sử dụng headless browser như Puppeteer hoặc Playwright.
Thay đổi cấu trúc HTML
Trang web thường xuyên cập nhật giao diện, khiến selector của scraper bị hỏng. Cần thiết kế scraper linh hoạt và có hệ thống giám sát để phát hiện lỗi sớm.
Xử lý dữ liệu lớn
Thu thập hàng triệu trang đòi hỏi hệ thống có khả năng xử lý song song, quản lý hàng đợi (queue) và lưu trữ hiệu quả.
Vai trò của Proxy trong Web Scraping
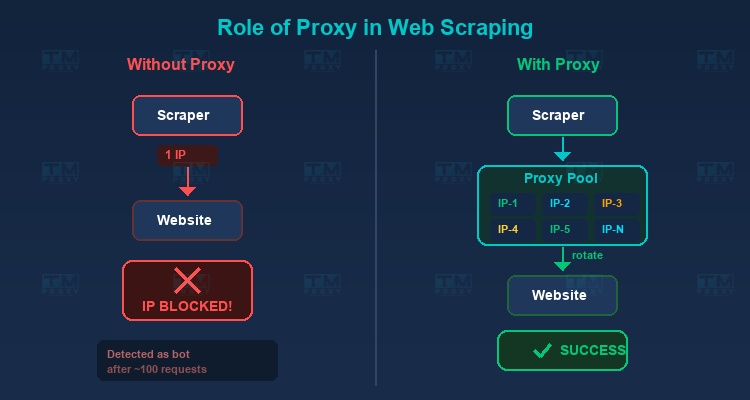
Proxy là thành phần không thể thiếu trong bất kỳ dự án web scraping quy mô nào. Đây là lý do:
Tránh bị chặn IP
Khi gửi hàng nghìn request từ cùng một IP, trang web sẽ nhanh chóng phát hiện và chặn bạn. Proxy cho phép bạn xoay IP liên tục, phân tán request qua nhiều địa chỉ IP khác nhau.
Vượt qua giới hạn địa lý
Một số trang web hiển thị nội dung khác nhau tùy theo vị trí địa lý. Proxy từ các quốc gia khác nhau cho phép bạn truy cập nội dung ở bất kỳ khu vực nào.
Tăng tốc độ thu thập
Sử dụng nhiều proxy đồng thời cho phép gửi request song song, tăng tốc độ scraping đáng kể mà không vượt quá giới hạn rate limit của mỗi IP.
Các loại proxy phù hợp cho scraping
-
Residential Proxy: Lựa chọn tốt nhất cho scraping. IP thật từ ISP nên rất khó bị phát hiện là bot. Phù hợp cho các trang web có cơ chế chống scraping mạnh.
-
Datacenter Proxy: Tốc độ cao, giá rẻ hơn. Phù hợp cho scraping các trang web ít bảo vệ hoặc có rate limit thấp.
-
Rotating Proxy: Tự động đổi IP sau mỗi request hoặc sau khoảng thời gian nhất định. Lý tưởng cho scraping quy mô lớn.
| Loại proxy | Tỷ lệ thành công | Tốc độ trung bình | IP bị chặn | Chi phí/10K trang |
|---|---|---|---|---|
| Residential | 98.5% | 1.2s/trang | 0.3% | $$ |
| Datacenter | 72% | 0.4s/trang | 28% | $ |
| Rotating Residential | 99.2% | 1.5s/trang | 0.1% | $$$ |
Rotating residential proxy đạt tỷ lệ thành công cao nhất (99.2%) với gần như không bị chặn IP. Datacenter proxy nhanh hơn nhưng 28% request bị block.
TMProxy cung cấp tất cả các loại proxy trên với hơn 10 triệu IP từ 200+ quốc gia, hỗ trợ xoay IP tự động — giải pháp hoàn hảo cho web scraping chuyên nghiệp.
Ứng dụng thực tế của Web Scraping
Theo dõi giá cả (Price Monitoring)
Các doanh nghiệp thương mại điện tử sử dụng scraping để theo dõi giá sản phẩm của đối thủ cạnh tranh theo thời gian thực, từ đó điều chỉnh chiến lược giá phù hợp.
Nghiên cứu thị trường
Thu thập đánh giá sản phẩm, bình luận trên mạng xã hội và xu hướng tìm kiếm để hiểu nhu cầu và tâm lý khách hàng.
Tuyển dụng (HR Tech)
Thu thập thông tin tuyển dụng từ các trang việc làm để phân tích xu hướng thị trường lao động, mức lương và kỹ năng được yêu cầu.
Bất động sản
Thu thập danh sách bất động sản, giá cả và thông tin khu vực từ các trang web bất động sản để phân tích thị trường.
SEO và Digital Marketing
Theo dõi thứ hạng từ khóa, phân tích backlink của đối thủ và thu thập dữ liệu SERP (Search Engine Results Page).
Lưu ý pháp lý khi thực hiện Web Scraping
Web scraping không phải lúc nào cũng hợp pháp. Bạn cần lưu ý:
-
Điều khoản dịch vụ (ToS): Nhiều trang web cấm scraping trong điều khoản sử dụng. Vi phạm có thể dẫn đến hậu quả pháp lý.
-
Robots.txt: File này chỉ định những phần nào của trang web cho phép hoặc không cho phép bot truy cập. Nên tôn trọng file robots.txt.
-
Dữ liệu cá nhân: Thu thập dữ liệu cá nhân phải tuân thủ các quy định bảo vệ dữ liệu như GDPR (Châu Âu), CCPA (California).
-
Bản quyền: Nội dung được bảo vệ bản quyền không nên được sao chép hoặc tái phân phối mà không có sự cho phép.
Thực hành tốt nhất cho Web Scraping hiệu quả
Để xây dựng hệ thống scraping bền vững và chuyên nghiệp, hãy tuân thủ các nguyên tắc sau:
Tôn trọng robots.txt
Luôn kiểm tra và tuân thủ file robots.txt của trang web trước khi scraping. File này chỉ định những URL nào bot được phép và không được phép truy cập. Mặc dù robots.txt không có tính ràng buộc pháp lý tuyệt đối, việc tôn trọng nó thể hiện đạo đức nghề nghiệp và giảm nguy cơ bị chặn.
Kiểm soát tốc độ request (Rate Limiting)
Không gửi request quá nhanh — điều này có thể làm quá tải server mục tiêu và khiến IP bạn bị chặn ngay lập tức. Đặt khoảng cách tối thiểu 1-3 giây giữa các request, hoặc điều chỉnh theo rate limit mà trang web cho phép.
Sử dụng Rotating Proxy
Xoay IP liên tục là yếu tố sống còn cho scraping quy mô lớn. Một pool proxy đa dạng với IP từ nhiều quốc gia và ISP khác nhau giúp phân tán request và tránh bị phát hiện. TMProxy cung cấp hơn 10 triệu IP residential với khả năng xoay tự động, lý tưởng cho mọi dự án scraping.
Giả lập User-Agent và Headers
Gửi request với headers giống trình duyệt thật: User-Agent, Accept, Accept-Language, Referer. Xoay User-Agent giữa các request để tránh bị phát hiện dựa trên fingerprint. Sử dụng danh sách User-Agent cập nhật từ các trình duyệt phổ biến.
Xử lý lỗi với Exponential Backoff
Khi gặp lỗi (HTTP 429, 503, timeout), không retry ngay lập tức. Sử dụng exponential backoff — chờ 1s, rồi 2s, 4s, 8s... Đặt giới hạn retry tối đa (thường 3-5 lần) để tránh vòng lặp vô hạn. Ghi log lỗi để phân tích và cải thiện scraper.
Lưu trữ HTML thô trước khi parse
Luôn lưu HTML thô của trang vào storage (file hoặc database) trước khi trích xuất dữ liệu. Điều này cho phép bạn re-parse dữ liệu khi logic trích xuất thay đổi mà không cần scrape lại, tiết kiệm thời gian và bandwidth đáng kể.
Giám sát và cảnh báo
Thiết lập hệ thống monitoring để theo dõi: tỷ lệ request thành công, tốc độ scraping, số lượng IP bị chặn, và chất lượng dữ liệu thu thập. Cảnh báo tự động khi tỷ lệ lỗi vượt ngưỡng giúp phát hiện và xử lý vấn đề nhanh chóng.
Ví dụ code Web Scraping với Python
Dưới đây là ví dụ đơn giản sử dụng Beautiful Soup để scrape tiêu đề sản phẩm và giá từ một trang web:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/products"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
# Sử dụng proxy để tránh bị chặn
proxies = {"http": "http://user:pass@proxy.tmproxy.com:8080",
"https": "http://user:pass@proxy.tmproxy.com:8080"}
response = requests.get(url, headers=headers, proxies=proxies, timeout=30)
soup = BeautifulSoup(response.text, "html.parser")
products = soup.select(".product-item")
for product in products:
name = product.select_one(".product-name").text.strip()
price = product.select_one(".product-price").text.strip()
print(f"{name}: {price}")
Ví dụ trên minh họa các best practice: sử dụng User-Agent header, proxy, timeout và CSS selectors để trích xuất dữ liệu có cấu trúc.
Xu hướng Web Scraping trong tương lai
Scraping hỗ trợ bởi AI
Trí tuệ nhân tạo đang thay đổi cách scraping hoạt động. Các công cụ AI có thể tự động nhận diện cấu trúc trang web, thích ứng khi layout thay đổi, và trích xuất dữ liệu mà không cần viết selector thủ công. Machine learning giúp scraper "học" từ các mẫu HTML và tự điều chỉnh khi trang web cập nhật.
Headless Browser trở thành tiêu chuẩn
Với sự phổ biến của Single Page Applications (SPA) và JavaScript-heavy websites, headless browser như Puppeteer và Playwright đã trở thành công cụ mặc định thay vì chỉ là giải pháp dự phòng. Các trang web hiện đại yêu cầu thực thi JavaScript để render nội dung, khiến HTTP request đơn thuần không còn đủ.
Cơ chế chống bot ngày càng tinh vi
Cloudflare, Akamai và các CDN khác liên tục cải thiện khả năng phát hiện bot. Các kỹ thuật mới bao gồm: phân tích hành vi chuột và bàn phím, TLS fingerprinting, phát hiện headless browser thông qua JavaScript API. Điều này đòi hỏi scraper phải ngày càng tinh vi hơn.
Scraping-as-a-Service phát triển mạnh
Nhiều doanh nghiệp chuyển sang sử dụng dịch vụ scraping bên ngoài thay vì tự xây dựng hạ tầng. Các nền tảng như Apify, ScrapingBee và Bright Data cung cấp API đơn giản, xử lý proxy rotation, CAPTCHA solving và browser rendering — giúp doanh nghiệp tập trung vào phân tích dữ liệu thay vì vận hành hạ tầng.
Scraping có đạo đức và tuân thủ pháp luật
Xu hướng ngày càng rõ ràng là cộng đồng scraping chú trọng hơn đến đạo đức và pháp lý. Các tiêu chuẩn và best practice được thiết lập rõ ràng hơn. Doanh nghiệp đầu tư vào compliance, tôn trọng ToS và dữ liệu cá nhân. Điều này giúp ngành web scraping phát triển bền vững và được chấp nhận rộng rãi hơn.
Kết luận: Web Scraping là kỹ thuật mạnh mẽ giúp doanh nghiệp thu thập và tận dụng dữ liệu web hiệu quả. Để triển khai thành công ở quy mô lớn, bạn cần hệ thống proxy đáng tin cậy, công cụ scraping phù hợp và kiến thức pháp lý vững vàng. Kết hợp đúng đắn giữa công cụ và chiến lược, web scraping có thể mang lại giá trị to lớn cho doanh nghiệp.