









网页爬虫是自动从网站收集数据的技术,帮助企业以人工无法实现的速度和规模提取信息。本文详细解释什么是网页爬虫、其工作原理、常用工具、代理的作用以及重要的法律注意事项。
什么是网页爬虫?
网页爬虫(也称为网页采集或网络数据提取)是使用软件或脚本自动访问网站并从其HTML源代码中提取结构化数据的过程。无需手动复制每条信息,网页爬虫让您在几分钟内就能收集数百万个数据点。
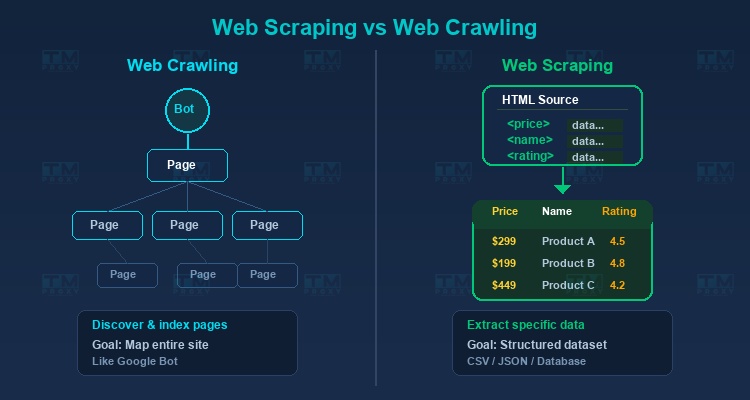
网页爬虫与网络爬虫的区别
许多人混淆了这两个概念:
-
**网络爬虫(Web Crawling)**是浏览和索引网页的过程,类似于Google Bot的工作方式。其主要目标是发现和映射网站结构。
-
**网页爬虫(Web Scraping)**专注于从已知页面提取特定数据。例如:获取产品价格、客户评价或联系信息。
在实践中,数据收集项目通常将两者结合:通过爬虫找到所需的URL,然后通过网页爬虫从每个URL中提取数据。
高速代理 - 准备试用?
ALGO Proxy 提供住宅、数据中心和 4G 代理,覆盖 195+ 国家
网页爬虫如何工作?
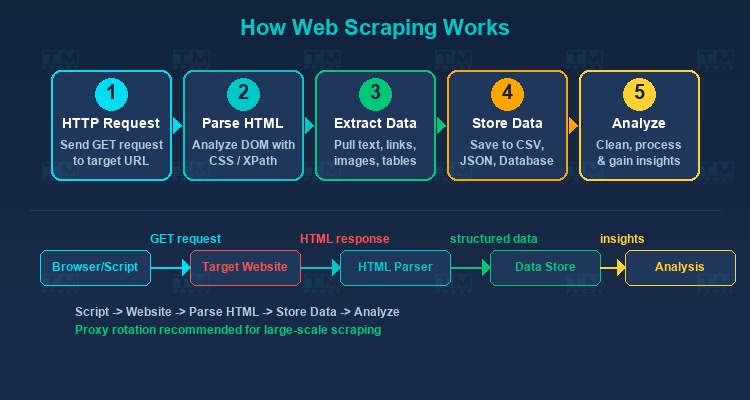
网页爬虫的基本工作流程包括以下步骤:
发送HTTP请求
脚本向目标URL发送HTTP请求(通常是GET),就像您的浏览器访问网页一样。服务器返回页面的HTML代码。
解析HTML
收到HTML后,爬虫工具分析DOM(文档对象模型)结构以确定目标数据的位置。常用方法包括:
- CSS选择器: 根据class、id或HTML结构选择元素。
- XPath: 一种强大的XML/HTML查询语言,允许在DOM结构中精确导航。
- 正则表达式: 在HTML中搜索特定的文本模式。
提取数据
从已识别的HTML元素中提取数据——可以是文本、属性(href、src)、表格或页面上显示的任何内容。
存储数据
提取的数据保存为CSV、JSON、Excel等结构化格式或存入数据库(MySQL、PostgreSQL、MongoDB)。
处理和分析
对原始数据进行清洗、标准化和分析,以获得有价值的商业洞察。
常用网页爬虫工具
编程库
-
Beautiful Soup(Python): 简单易用的HTML/XML解析库。适合中小型爬虫项目。
-
Scrapy(Python): 强大而完整的爬虫框架。支持异步处理、数据管道和中间件。适合大规模项目。
-
Puppeteer(Node.js): 用于控制无头Chrome/Chromium浏览器的库。擅长处理使用JavaScript渲染的网站。
-
Playwright(多语言): 类似Puppeteer,但支持多种浏览器(Chrome、Firefox、Safari)和多种编程语言。
-
Selenium: 浏览器自动化工具,允许像真实用户一样与网站交互(点击、滚动、填写表单)。
无代码平台
-
Octoparse: 直观的拖放界面,无需编写代码。适合没有编程经验的用户。
-
ParseHub: 类似Octoparse,支持爬取使用JavaScript的复杂网站。
-
Apify: 基于云的平台,为许多流行网站提供现成的actor(脚本)。
网页爬虫的挑战
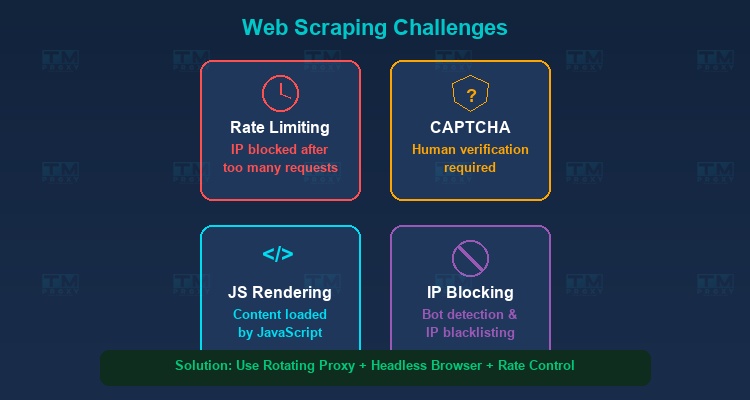
反爬机制
网站越来越多地实施阻止爬虫机器人的措施:
- 速率限制: 限制在给定时间内来自单个IP的请求数量。
- 验证码(CAPTCHA): 要求验证用户是人类。
- IP封锁: 封锁发送过多请求或表现出异常行为的IP。
- User-Agent检测: 检测并阻止不来自真实浏览器的请求。
- 蜜罐陷阱: 只有机器人才会访问的隐藏链接,用于识别爬虫。
JavaScript渲染
许多现代网站使用JavaScript渲染内容(单页应用程序 - SPA)。这意味着初始HTML不包含数据——数据只在JavaScript执行后才加载。解决方案是使用Puppeteer或Playwright等无头浏览器。
HTML结构变更
网站经常更新其界面,导致爬虫选择器失效。爬虫需要灵活设计,并配备监控系统以尽早发现错误。
大规模数据处理
收集数百万页面需要具备并行处理、队列管理和高效存储能力的系统。
代理在网页爬虫中的作用
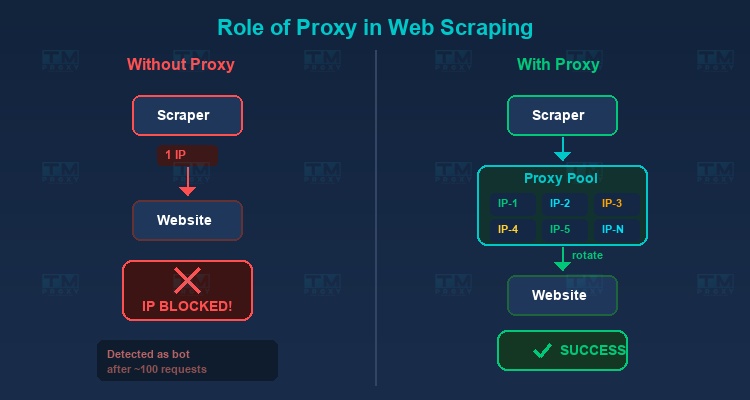
代理是任何大规模网页爬虫项目中不可或缺的组件。原因如下:
避免IP封锁
当从同一IP发送数千个请求时,网站会迅速检测并封锁您。代理允许您持续轮换IP,将请求分散到多个不同的IP地址。
绕过地理限制
一些网站根据地理位置显示不同的内容。来自不同国家的代理让您可以访问任何区域的内容。
提高采集速度
同时使用多个代理允许并行请求,在不超过每个IP的速率限制的情况下显著提高爬虫速度。
最适合爬虫的代理类型
-
住宅代理: 爬虫的最佳选择。来自ISP的真实IP,很难被检测为机器人。适合有强反爬机制的网站。
-
数据中心代理: 速度快,成本低。适合爬取保护较少或速率限制较低的网站。
-
轮换代理: 在每次请求后或设定时间段后自动更改IP。非常适合大规模爬虫。
| 代理类型 | 成功率 | 平均速度 | IP被封率 | 成本/万页 |
|---|---|---|---|---|
| 住宅代理 | 98.5% | 1.2秒/页 | 0.3% | $$ |
| 数据中心代理 | 72% | 0.4秒/页 | 28% | $ |
| 轮换住宅代理 | 99.2% | 1.5秒/页 | 0.1% | $$$ |
轮换住宅代理获得最高成功率(99.2%),几乎无IP被封。数据中心代理速度更快但28%的请求被拦截。
TMProxy提供所有这些代理类型,拥有来自200多个国家的超过1000万个IP,支持自动IP轮换——专业网页爬虫的完美解决方案。
网页爬虫的实际应用
价格监控
电商企业使用爬虫实时跟踪竞争对手的产品价格,从而相应调整定价策略。
市场研究
收集产品评价、社交媒体评论和搜索趋势,以了解客户需求和情绪。
人力资源科技
从招聘网站收集职位信息,分析劳动力市场趋势、薪资水平和需求技能。
房地产
从房地产网站收集房产列表、价格和区域信息以进行市场分析。
SEO和数字营销
跟踪关键词排名,分析竞争对手的反向链接,收集SERP(搜索引擎结果页面)数据。
网页爬虫的法律注意事项
网页爬虫并非在所有情况下都是合法的。您应注意:
-
服务条款(ToS): 许多网站在使用条款中禁止爬虫。违反可能导致法律后果。
-
Robots.txt: 该文件指定网站的哪些部分允许或不允许机器人访问。应当尊重robots.txt文件。
-
个人数据: 收集个人数据必须遵守GDPR(欧洲)、CCPA(加利福尼亚)等数据保护法规。
-
版权: 受版权保护的内容不应在未经许可的情况下复制或再分发。
高效网页爬虫的最佳实践
要构建可持续和专业的爬虫系统,请遵循以下关键原则:
尊重robots.txt
在爬取之前,始终检查并遵守目标网站的robots.txt文件。该文件指定哪些URL允许或禁止机器人访问。虽然robots.txt在所有司法管辖区并不具有法律约束力,但尊重它体现了职业道德,并降低了被封锁的风险。
实施速率限制
不要过快地发送请求——这可能使目标服务器过载并导致您的IP立即被封锁。在请求之间设置至少1-3秒的延迟,或根据网站允许的速率进行调整。
使用轮换代理
持续IP轮换对于大规模爬虫至关重要。拥有来自多个国家和ISP的多样化代理池有助于分散请求并避免被检测。TMProxy提供超过1000万个住宅IP,支持自动轮换,是任何爬虫项目的理想选择。
模拟真实的User-Agent和请求头
发送带有模拟真实浏览器头部的请求:User-Agent、Accept、Accept-Language、Referer。在请求之间轮换User-Agent以避免基于指纹的检测。使用来自流行浏览器的更新User-Agent列表。
使用指数退避处理错误
遇到错误(HTTP 429、503、超时)时,不要立即重试。使用指数退避——等待1秒,然后2秒、4秒、8秒……设置最大重试限制(通常3-5次)以避免无限循环。记录错误以进行分析和改进爬虫。
解析前存储原始HTML
始终在提取数据之前将页面的原始HTML保存到存储中(文件或数据库)。这样当提取逻辑发生变化时,您可以重新解析数据而无需重新爬取,节省大量时间和带宽。
建立监控和警报系统
建立监控系统来跟踪:请求成功率、爬取速度、被封锁的IP数量和数据质量。当错误率超过阈值时自动告警,有助于快速发现和解决问题。
Python网页爬虫代码示例
以下是使用Beautiful Soup从网站爬取产品标题和价格的简单示例:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/products"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
# 使用代理避免被封锁
proxies = {"http": "http://user:pass@proxy.tmproxy.com:8080",
"https": "http://user:pass@proxy.tmproxy.com:8080"}
response = requests.get(url, headers=headers, proxies=proxies, timeout=30)
soup = BeautifulSoup(response.text, "html.parser")
products = soup.select(".product-item")
for product in products:
name = product.select_one(".product-name").text.strip()
price = product.select_one(".product-price").text.strip()
print(f"{name}: {price}")
此示例展示了关键的最佳实践:使用User-Agent头部、代理、超时和CSS选择器进行结构化数据提取。
网页爬虫趋势
AI驱动的爬虫
人工智能正在改变爬虫的工作方式。AI工具可以自动识别页面结构、在布局变化时适应,并无需手动编写选择器即可提取数据。机器学习帮助爬虫从HTML模式中"学习",并在网站更新时自动调整。
无头浏览器成为标准
随着单页应用(SPA)和JavaScript密集型网站的兴起,Puppeteer和Playwright等无头浏览器已成为默认工具而非仅仅是备用方案。现代网站需要JavaScript执行才能渲染内容,使简单的HTTP请求不再足够。
日益复杂的反机器人措施
Cloudflare、Akamai和其他CDN不断提高其机器人检测能力。新技术包括:鼠标和键盘行为分析、TLS指纹识别、通过JavaScript API检测无头浏览器。这要求爬虫变得越来越复杂。
爬虫即服务的增长
许多企业正在转向使用外部爬虫服务,而不是构建自己的基础设施。Apify、ScrapingBee和Bright Data等平台提供简单的API,处理代理轮换、验证码解决和浏览器渲染——让企业专注于数据分析而不是基础设施管理。
道德和合规的爬虫实践
爬虫社区中道德实践和法律合规的趋势日益明显。标准和最佳实践正变得更加清晰。企业投资于合规性,尊重服务条款和个人数据法规。这有助于网页爬虫行业可持续发展并获得更广泛的接受。
总结: 网页爬虫是帮助企业高效收集和利用网络数据的强大技术。要成功实施大规模爬虫,您需要可靠的代理系统、合适的爬虫工具和扎实的法律知识。通过正确的工具和策略组合,网页爬虫可以为您的企业带来巨大价值。