









代理是AI数据收集的关键工具:绕过速率限制、收集多国数据、将管线扩展到数百万数据点。本文详细指导如何为每种AI工作负载选择合适的代理。
AI渴求数据 — 代理就是答案
高速代理 - 准备试用?
ALGO Proxy 提供住宅、数据中心和 4G 代理,覆盖 195+ 国家
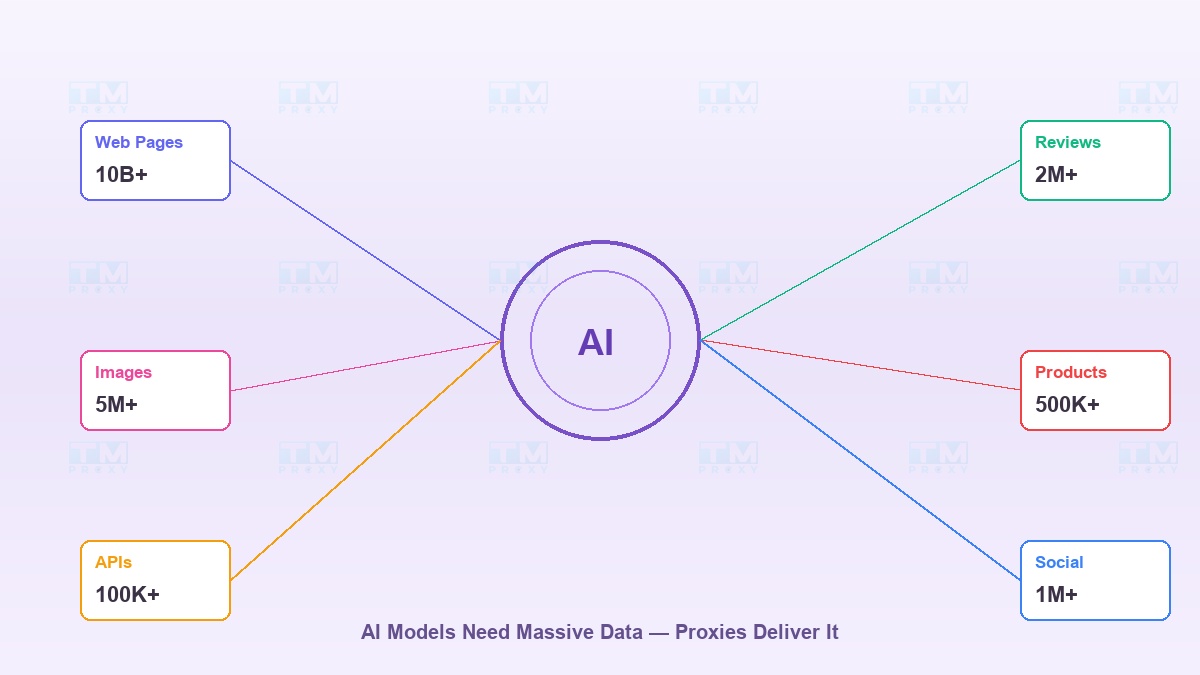
一个优秀的AI模型需要什么?数据。海量的数据。
GPT在数十亿网页上训练。图像识别模型需要数百万张照片。推荐系统需要来自数百个电商平台的产品数据。所有这些数据都在互联网上——但要获取它们却是一个完全不同的难题。
问题在于:网站不希望你爬取它们的数据。它们设置速率限制、封锁IP、要求验证码。这正是代理成为AI生态系统中不可或缺工具的原因。
在本文中,我们将深入探讨代理在AI开发每个阶段的作用——从收集训练数据到部署和监控。
收集AI数据的最大挑战

API速率限制
OpenAI限制60个请求/分钟。Google搜索API每天免费100个查询。Twitter API仅允许300个请求/15分钟。当你需要数百万个数据点时,这些限制就成了巨大的障碍。
解决方案: 代理池将请求分散到多个IP。1个IP = 60 req/min → 100个IP = 6,000 req/min。简单而有效。
地域差异化数据
Google搜索在美国、日本、越南返回不同的结果。Amazon按国家显示不同的价格和产品。如果你的AI模型需要理解多元文化背景,你必须从多个国家收集数据。
解决方案: 100+国家的代理让你"坐在一个国家,却能像美国人、日本人一样看互联网。"
海量数据规模
训练一个LLM需要TB级的文本数据。计算机视觉需要数百万张图像。以1个IP每秒1个请求的速度,你需要数月才能收集够。用1,000个代理并行运行,这个时间缩短到几天。
适配每种AI工作负载的代理
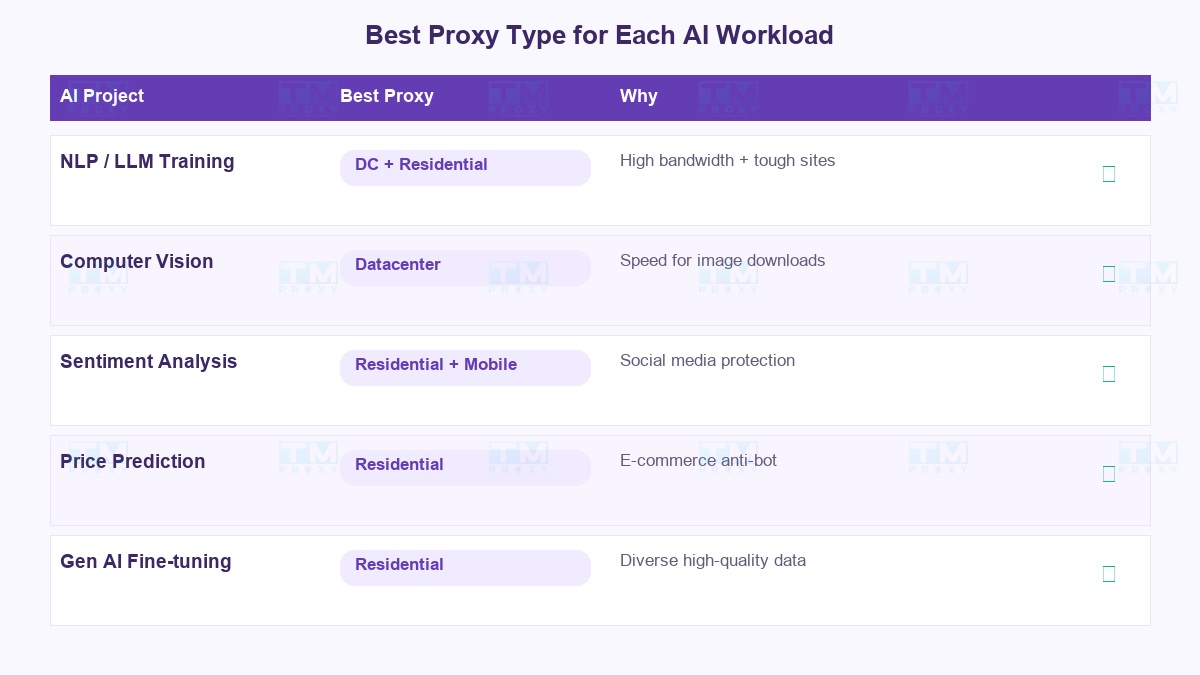
每种AI项目需要不同的代理。没有"万能通用"的方案:
| AI项目类型 | 最佳代理 | 原因 |
|---|---|---|
| NLP / LLM训练 | 数据中心 + 住宅 | 文本数据需要大带宽,难抓的站点用住宅代理 |
| 计算机视觉 | 数据中心 | 下载图片需要速度,图片通常是公开的所以很少被封 |
| 情感分析 | 住宅 + 移动 | 社交媒体保护严格,需要可信IP |
| 价格预测 | 住宅 | 电商网站有强大的反机器人系统 |
| 生成式AI微调 | 住宅 | 需要来自多样化来源的高质量数据 |
| 代理类型 | 成功率 | 速度 (req/s) | 每百万请求成本 | 适用场景 |
|---|---|---|---|---|
| 数据中心 | 62% | 500+ | $ | API、论坛、博客 |
| 住宅 | 94% | 50-100 | $$$ | 电商、社交媒体 |
| 移动 | 98% | 20-50 | $$$$$ | 高度保护的社交媒体 |
住宅代理在大多数AI数据源上达到最高成功率(94%)。数据中心代理以最低成本适合保护较弱的数据源。
数据中心代理适用于:需要高速、大带宽,且目标网站保护较弱。成本最低,适合大量API调用。
住宅代理适用于:目标网站有反机器人系统(Google、Amazon、社交媒体)。来自ISP的真实IP,成功率高。大多数AI项目的最安全选择。
移动代理适用于:从移动应用或保护严格的社交媒体收集数据。最贵但几乎永远不会被封。
AI数据收集管线:从构想到模型
以下是专业AI团队使用的实际工作流程:
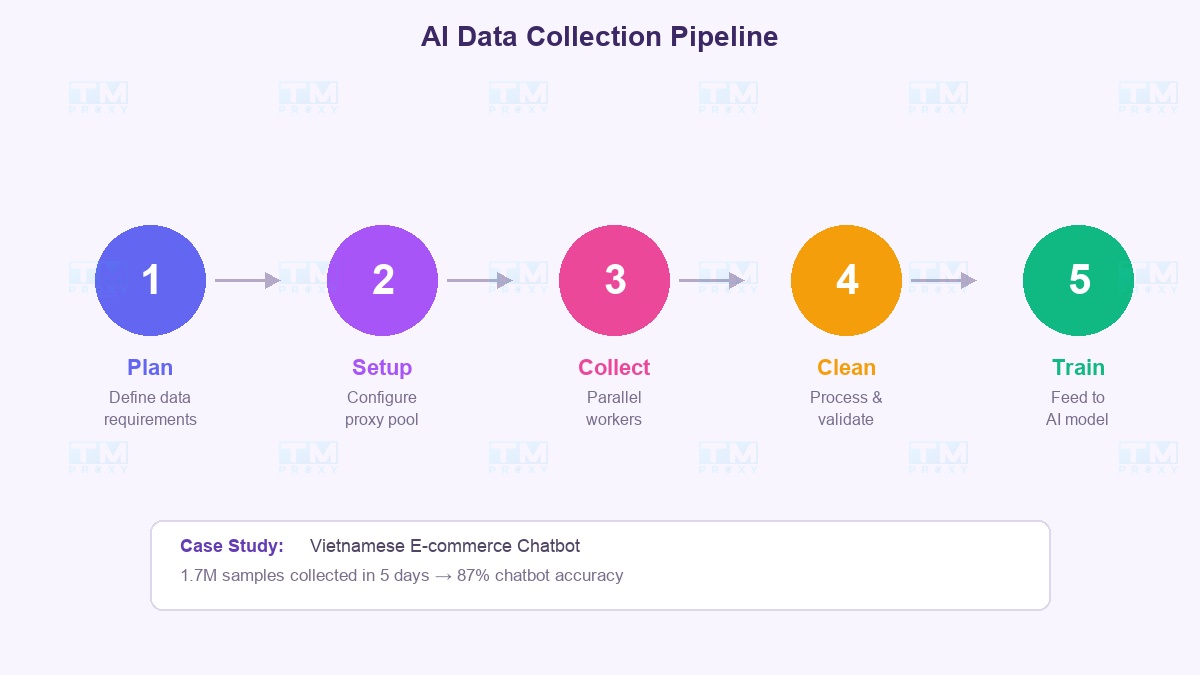
阶段1 → 规划 明确定义:需要多少数据?来自哪些来源?更新频率?例如:"需要来自5个电商平台的100万条越南语产品评论,每日更新。"
阶段2 → 代理基础设施搭建 选择服务商,配置代理池,在目标网站测试成功率。从100个IP开始,逐步扩展。
阶段3 → 并行收集 同时运行多个worker,每个使用独立代理。管线:请求 → 解析 → 验证 → 存储。收集速度与代理数量成正比。
阶段4 → 处理和清洗 去重、过滤噪声、标准化格式。此步骤与收集并行运行——无需等收集完成。
阶段5 → 训练和评估 将数据输入模型,评估结果。如果质量不够 → 回到阶段1使用新数据源。
案例研究:为越南语聊天机器人收集数据
一个真实项目:为越南电商构建客服聊天机器人。
数据需求:
- 50万条来自支持论坛的问答对
- 20万条来自Shopee、Lazada、Tiki的产品描述
- 100万条带评分的产品评论
代理方案:
- 越南住宅代理用于Shopee、Lazada(强反机器人)
- 数据中心代理用于论坛、博客(保护较弱)
- 轮换:每5个请求换IP,延迟3-5秒
结果:
- 5天内完成收集,不使用代理预计需要2个月
- 成功率:94%(住宅)和78%(数据中心)
- 聊天机器人在此数据集上训练后达到87%的准确率
收集AI数据的重要注意事项
为AI收集数据不仅仅是技术问题。请注意:
- GDPR与隐私: 欧盟的个人数据需要严格合规。训练前对数据进行匿名化处理。
- robots.txt: 务必检查并遵守。除了法律问题,许多反机器人系统把它用作蜜罐。
- 服务条款: 每个网站有自己的ToS。大规模爬取前仔细阅读。
- 数据质量 > 数量: 10万条高质量样本胜过100万条带噪声的。在数据清洗上投入资源。
- 持续监控: 网站结构经常变化。需要24/7监控管线。
TMProxy助力AI项目
TMProxy 深知AI工作负载与普通浏览有着本质区别。我们提供:
- 用于数据收集: 覆盖100+国家的数百万住宅IP池。不限带宽。轻松集成到Python/Node.js管线的API。
- 用于API访问: 高速低延迟的数据中心代理。需要保持上下文时支持固定会话。
- 用于团队: 使用量管理仪表板、按项目分权限、透明计费。
总结: 在AI竞赛中,数据是燃料,代理是输送燃料的管道。投资优质代理基础设施不是成本——而是竞争优势。让TMProxy帮你更快地构建更好的AI。