









Proxy là công cụ then chốt cho thu thập dữ liệu AI: vượt qua rate limiting, thu thập data đa quốc gia, và scale pipeline lên hàng triệu data points. Bài viết hướng dẫn chi tiết cách chọn proxy phù hợp cho từng loại AI workload.
AI đang khát dữ liệu — và Proxy là giải pháp
Proxy tốc độ cao – Sẵn sàng dùng thử?
ALGO Proxy cung cấp proxy residential, datacenter và 4G tại 195+ quốc gia
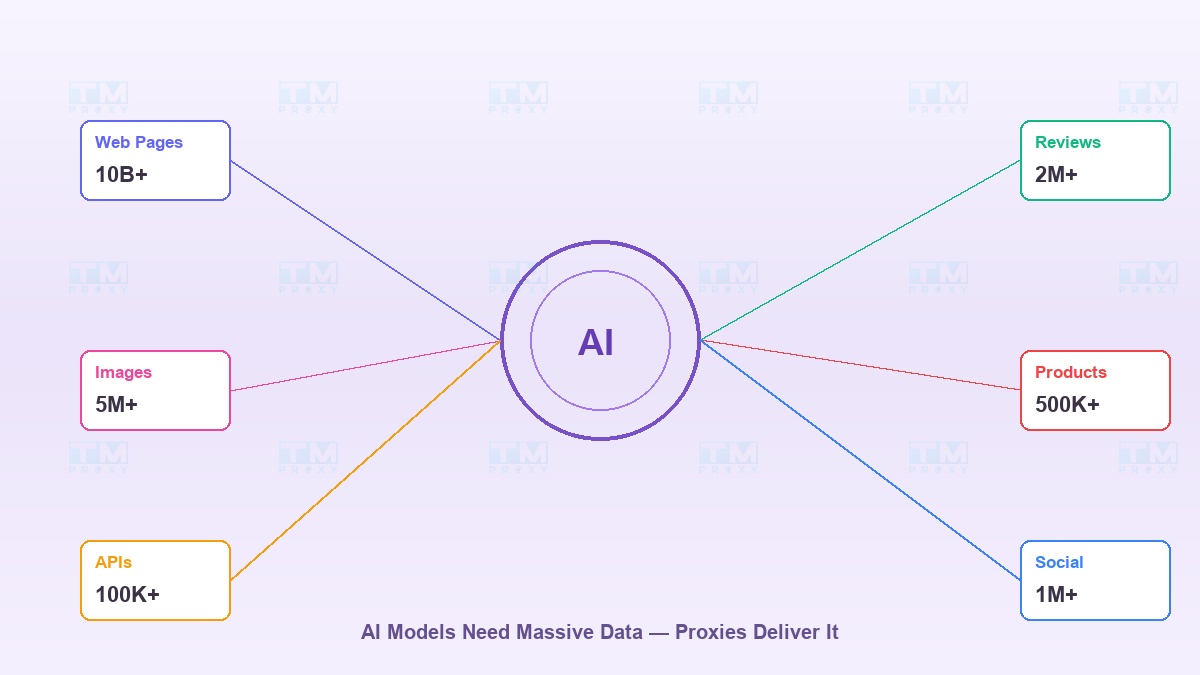
Một mô hình AI giỏi cần gì? Dữ liệu. Rất nhiều dữ liệu.
GPT được huấn luyện trên hàng tỷ trang web. Mô hình nhận diện hình ảnh cần hàng triệu bức ảnh. Hệ thống recommendation cần dữ liệu sản phẩm từ hàng trăm sàn thương mại. Tất cả dữ liệu này đều nằm trên internet — nhưng lấy được nó lại là một bài toán hoàn toàn khác.
Vấn đề nằm ở chỗ: các website không muốn bạn crawl dữ liệu của họ. Họ đặt rate limit, chặn IP, yêu cầu CAPTCHA. Và đó chính là lý do proxy trở thành công cụ không thể thiếu trong hệ sinh thái AI.
Trong bài viết này, chúng ta sẽ đi sâu vào vai trò của proxy trong từng giai đoạn phát triển AI — từ thu thập training data đến deployment và monitoring.
Thách thức lớn nhất khi thu thập dữ liệu cho AI

Rate Limiting của API
OpenAI giới hạn 60 request/phút. Google Search API cho 100 query/ngày miễn phí. Twitter API chỉ cho 300 request/15 phút. Khi bạn cần hàng triệu data point, những giới hạn này trở thành rào cản khổng lồ.
Giải pháp: Proxy pool phân tán request qua nhiều IP. 1 IP = 60 req/phút → 100 IP = 6000 req/phút. Đơn giản mà hiệu quả.
Dữ liệu khác nhau theo vùng địa lý
Google Search trả kết quả khác nhau tại Mỹ, Nhật, Việt Nam. Amazon hiển thị giá và sản phẩm khác theo quốc gia. Nếu mô hình AI của bạn cần hiểu ngữ cảnh đa văn hóa, bạn phải thu thập dữ liệu từ nhiều quốc gia.
Giải pháp: Proxy tại 100+ quốc gia giúp bạn "ngồi tại Việt Nam mà thấy internet như người Mỹ, người Nhật."
Quy mô dữ liệu khổng lồ
Huấn luyện một LLM cần hàng TB dữ liệu text. Computer Vision cần hàng triệu ảnh. Với tốc độ 1 request/giây từ 1 IP, bạn cần hàng tháng để thu thập đủ. Với 1000 proxy chạy song song, con số đó giảm xuống vài ngày.
Proxy phù hợp cho từng loại AI Workload
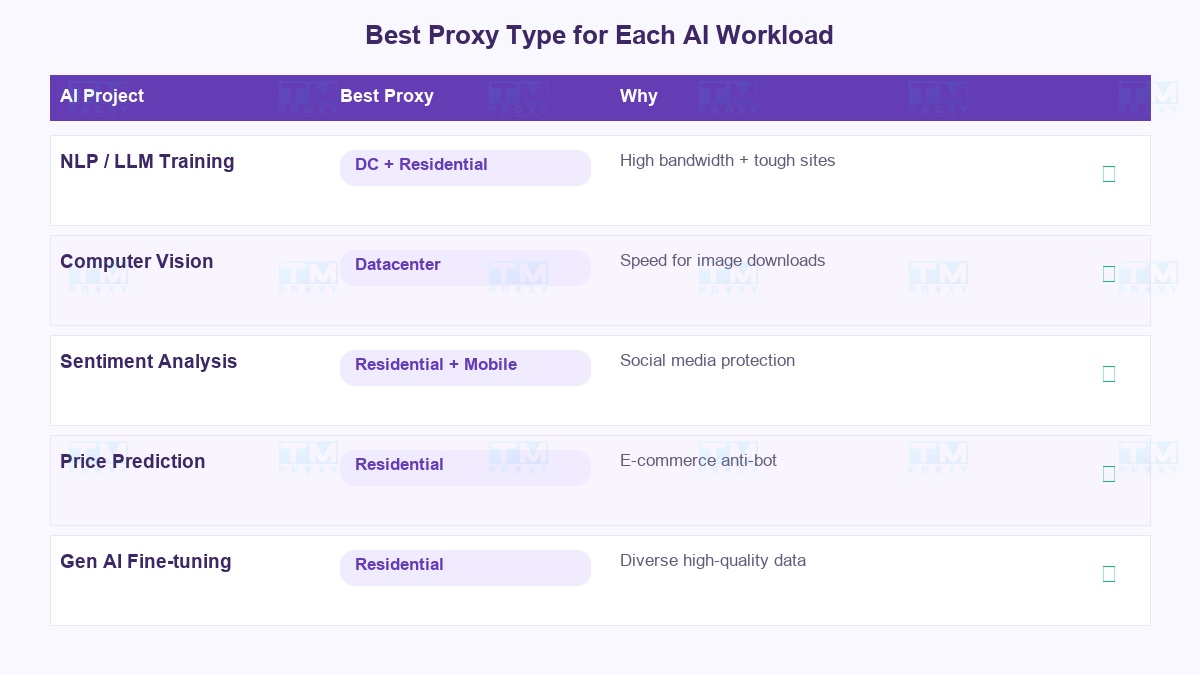
Mỗi loại dự án AI cần proxy khác nhau. Không có "one-size-fits-all":
| Loại AI Project | Proxy phù hợp | Lý do |
|---|---|---|
| NLP / LLM Training | Datacenter + Residential | Cần băng thông lớn cho text data, residential cho site khó |
| Computer Vision | Datacenter | Tải ảnh cần tốc độ cao, ít bị chặn vì ảnh thường public |
| Sentiment Analysis | Residential + Mobile | Social media có bảo vệ chặt, cần IP đáng tin cậy |
| Price Prediction | Residential | E-commerce sites có anti-bot mạnh |
| Generative AI Fine-tuning | Residential | Cần dữ liệu chất lượng cao từ nhiều nguồn diverse |
| Loại Proxy | Tỷ lệ thành công | Tốc độ (req/s) | Chi phí/1M requests | Phù hợp cho |
|---|---|---|---|---|
| Datacenter | 62% | 500+ | $ | API, forum, blog |
| Residential | 94% | 50-100 | $$$ | E-commerce, social media |
| Mobile | 98% | 20-50 | $$$$$ | Social media bảo vệ cao |
Residential proxy đạt tỷ lệ thành công cao nhất cho đa số nguồn dữ liệu AI (94%). Datacenter proxy phù hợp cho nguồn ít bảo vệ với chi phí thấp nhất.
Datacenter Proxy phù hợp khi: bạn cần tốc độ cao, băng thông lớn, và target website ít bảo vệ. Chi phí thấp nhất, lý tưởng cho gọi API khối lượng lớn.
Residential Proxy phù hợp khi: target website có anti-bot (Google, Amazon, social media). IP thật từ ISP, tỷ lệ thành công cao. Đây là lựa chọn an toàn nhất cho hầu hết dự án AI.
Mobile Proxy phù hợp khi: thu thập dữ liệu từ ứng dụng mobile hoặc social media có bảo vệ nghiêm ngặt. Đắt nhất nhưng gần như không bao giờ bị chặn.
Pipeline thu thập dữ liệu AI: Từ ý tưởng đến model
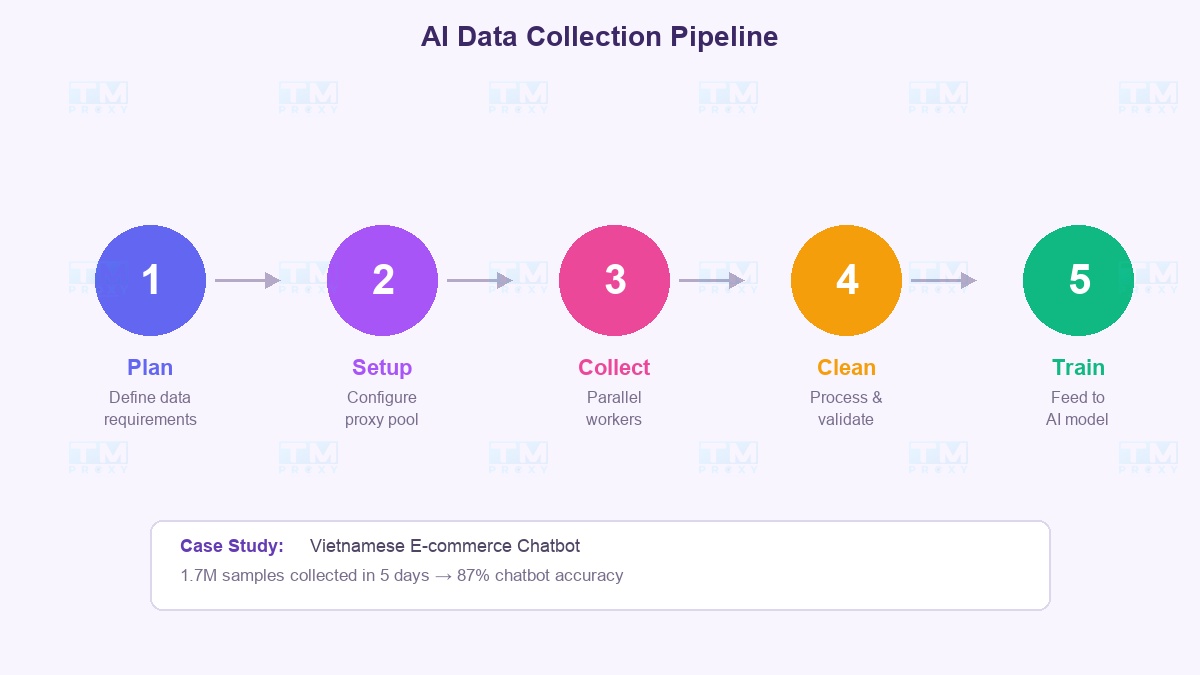
Đây là workflow thực tế mà các team AI chuyên nghiệp sử dụng:
Giai đoạn 1 → Lập kế hoạch Xác định rõ: Cần bao nhiêu data? Từ nguồn nào? Frequency ra sao? Ví dụ: "Cần 1 triệu review sản phẩm tiếng Việt từ 5 sàn TMĐT, cập nhật hàng ngày."
Giai đoạn 2 → Thiết lập hạ tầng proxy Chọn provider, cấu hình proxy pool, test tỷ lệ thành công trên target website. Bắt đầu với 100 IP, scale lên dần.
Giai đoạn 3 → Thu thập song song Chạy nhiều worker đồng thời, mỗi worker dùng proxy riêng. Pipeline: Request → Parse → Validate → Store. Tốc độ thu thập tỷ lệ thuận với số proxy.
Giai đoạn 4 → Xử lý và làm sạch Loại bỏ duplicate, filter noise, chuẩn hóa format. Bước này chạy song song với thu thập — không cần chờ thu thập xong mới xử lý.
Giai đoạn 5 → Huấn luyện và đánh giá Feed dữ liệu vào model, đánh giá kết quả. Nếu quality chưa đủ → quay lại giai đoạn 1 với nguồn dữ liệu mới.
Case Study: Thu thập dữ liệu cho Chatbot tiếng Việt
Một dự án thực tế: Xây dựng chatbot hỗ trợ khách hàng cho ngành TMĐT Việt Nam.
Yêu cầu dữ liệu:
- 500K câu hỏi - trả lời từ các forum hỗ trợ
- 200K mô tả sản phẩm từ Shopee, Lazada, Tiki
- 1M review sản phẩm có rating
Giải pháp proxy:
- Residential proxy Việt Nam cho Shopee, Lazada (anti-bot mạnh)
- Datacenter proxy cho các forum, blog (ít bảo vệ)
- Rotation: đổi IP sau mỗi 5 request, delay 3-5 giây
Kết quả:
- Thu thập xong trong 5 ngày thay vì ước tính 2 tháng không dùng proxy
- Tỷ lệ thành công: 94% (residential) và 78% (datacenter)
- Chatbot đạt accuracy 87% sau khi huấn luyện trên dataset này
Lưu ý quan trọng khi thu thập dữ liệu cho AI
Thu thập dữ liệu cho AI không chỉ là vấn đề kỹ thuật. Hãy lưu ý:
- GDPR & Privacy: Dữ liệu cá nhân tại EU cần tuân thủ nghiêm ngặt. Anonymize data trước khi dùng cho training.
- robots.txt: Luôn check và tôn trọng. Ngoài vấn đề pháp lý, nhiều anti-bot dùng nó như honeypot.
- Terms of Service: Mỗi website có ToS riêng. Đọc kỹ trước khi scrape quy mô lớn.
- Data Quality > Quantity: 100K sample chất lượng tốt hơn 1M sample nhiễu. Invest vào data cleaning.
- Giám sát liên tục: Website thay đổi cấu trúc thường xuyên. Cần monitoring pipeline 24/7.
TMProxy cho các dự án AI
TMProxy hiểu rằng AI workload khác biệt hoàn toàn so với browsing thông thường. Chúng tôi cung cấp:
- Cho thu thập dữ liệu: Pool hàng triệu IP residential tại 100+ quốc gia. Băng thông không giới hạn. API tích hợp dễ dàng vào pipeline Python/Node.js.
- Cho truy cập API: Datacenter proxy tốc độ cao, latency thấp. Hỗ trợ sticky session khi cần duy trì context.
- Cho team: Dashboard quản lý usage, phân quyền theo project, billing minh bạch.
Kết luận: Trong cuộc đua AI, data là nhiên liệu và proxy là đường ống dẫn nhiên liệu đó. Đầu tư vào hạ tầng proxy chất lượng không phải chi phí — mà là lợi thế cạnh tranh. Hãy để TMProxy giúp bạn xây dựng AI tốt hơn, nhanh hơn.