









Apache Spark is an open-source cluster computing platform that processes big data in memory, up to 100 times faster than Hadoop MapReduce. This article analyzes the architecture, main components, and practical applications of Apache Spark.
High-Speed Proxy - Ready to Try?
ALGO Proxy offers residential, datacenter & 4G proxies in 195+ countries
What is Apache Spark?
Apache Spark is an open-source cluster computing platform designed to process data quickly and efficiently. It provides a unified programming interface for big data processing, including tasks such as SQL queries, streaming, machine learning, and graph analytics. Spark was developed to overcome the limitations of the traditional MapReduce model while delivering significantly higher performance in data processing.
One of the standout advantages of Apache Spark is its in-memory processing capability. This allows Spark to perform tasks many times faster than other big data processing solutions, especially for iterative algorithms such as those used in machine learning.

Main Components of Apache Spark
Apache Spark consists of multiple components, each designed to handle specific types of tasks. Below are the main components of Apache Spark:
Spark Core
Spark Core is the fundamental foundation of the entire Apache Spark system. It provides basic functions such as task scheduling, memory management, fault recovery, and interaction with storage systems. Spark Core also defines the API for Resilient Distributed Datasets (RDDs), a fundamental distributed data structure in Spark.
RDDs allow programmers to perform computations on large datasets transparently across multiple computers in a cluster. Spark Core also provides numerous APIs for building and manipulating RDDs.
Spark SQL
Spark SQL is a Spark module that enables working with structured data. It provides a programming interface for manipulating data through SQL as well as Hive Query Language (HQL). Spark SQL not only supports SQL queries but also allows you to mix SQL queries with data operations programmed in Python, Java, and Scala.
One of the important features of Spark SQL is the ability to access data from various sources such as Hive, Avro, Parquet, ORC, JSON, and JDBC. Additionally, Spark SQL provides a query optimization engine called Catalyst, which significantly improves query performance.
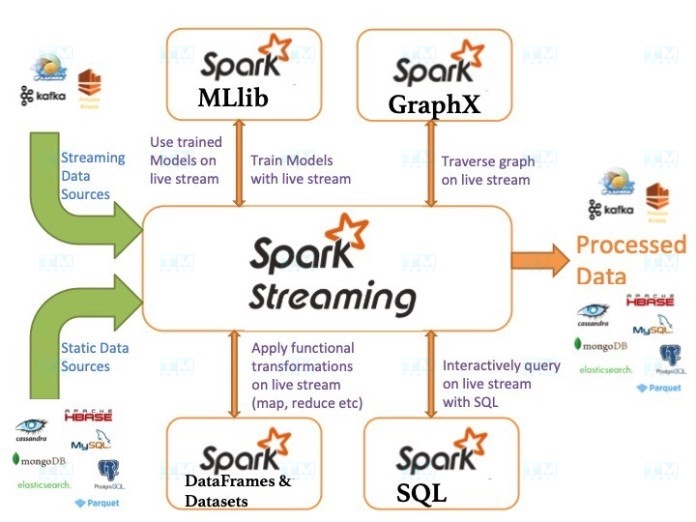
Spark Streaming
Spark Streaming is an extension of the Spark Core API that enables low-latency, fault-tolerant stream data processing. It can process data from multiple sources such as Kafka, Flume, Twitter, ZeroMQ, or TCP sockets and can process data using complex algorithms expressed through functions like map, reduce, join, and window.
Spark Streaming divides streaming data into micro-batches and processes them using the Spark Core engine. This allows Spark Streaming applications to be written similarly to batch processing applications, simplifying the development process.
Spark MLlib (Machine Learning Library)
MLlib is Spark's machine learning library, providing numerous algorithms and utilities for machine learning. MLlib includes popular algorithms such as classification, regression, clustering, collaborative filtering, and dimensionality reduction. It also provides tools for feature extraction, transformation, model evaluation, and model persistence.
MLlib is designed to scale easily, leveraging Spark's distributed processing capability to train machine learning models on large datasets. This enables data scientists to apply complex machine learning algorithms on datasets up to petabytes in size.
GraphX
GraphX is a Spark component used for graph processing and performing parallel computations on graphs. It provides an API for expressing graph computations and a collection of pre-optimized graph algorithms.
GraphX extends Spark's RDD by introducing the Resilient Distributed Graph (RDG), a directed graph with properties attached to each vertex and edge. GraphX includes a growing collection of graph algorithms and graph building tools to simplify graph analytics tasks.
Apache Spark Architecture
The architecture of Apache Spark is designed to support efficient distributed data processing. It consists of two main components: the Driver Program and Worker Nodes.
- Driver Program: This is the main program that runs the main() function and creates the SparkContext. The SparkContext is the main entry point for all Spark functionalities. It coordinates all tasks running on the cluster.
- Worker Nodes: These are the nodes in the cluster responsible for executing tasks assigned by the Driver Program. Each Worker Node runs an Executor process, which is a Java process that runs tasks and keeps data in memory or on disk. When a Spark application runs, the Driver Program creates a DAG (Directed Acyclic Graph) of tasks to be executed on the cluster. This DAG is divided into stages, each stage consisting of tasks that can be executed in parallel.
SparkContext communicates with the Cluster Manager (such as YARN or Mesos) to distribute these tasks to Worker Nodes. Each Worker Node runs tasks in its Executors and reports results back to the Driver Program.

How Apache Spark Works
Apache Spark operates based on a distributed data processing model. Below is the basic workflow of how Spark processes data:
- Creating RDDs: Spark begins by creating Resilient Distributed Datasets (RDDs) from input data. RDDs are immutable collections of data distributed across nodes in the cluster.
- Transformations: Spark applies transformations (such as map, filter, groupBy) on RDDs to create new RDDs. These transformations are "lazy," meaning they are not executed immediately but only recorded.
- Actions: When an action (such as count, collect, save) is called, Spark creates a DAG (Directed Acyclic Graph) of tasks needed to produce the final result.
- Stage Division: The DAG is divided into stages. Each stage consists of tasks that can be executed in parallel on different data partitions.
- Task Scheduling: The Spark Scheduler distributes tasks to Executors on Worker Nodes in the cluster.
- Task Execution: Executors carry out the assigned tasks and store results in memory or on disk.
- Shuffling: If needed, data is shuffled between partitions (e.g., in operations like groupBy or join).
- Result Collection: The final results are collected and returned to the Driver Program.
One of Spark's strengths is its ability to cache data in memory. This allows iterative operations on the same dataset to be performed quickly, as data does not need to be re-read from disk on each iteration.

Benefits of Using Apache Spark
Apache Spark brings significant benefits to organizations and businesses in processing and analyzing big data:
- Fast processing speed: Spark can process data up to 100 times faster than Hadoop MapReduce in memory and 10 times faster on disk. This is due to Spark's in-memory processing capability and optimized execution engine.
- Versatility: Spark supports various types of data processing tasks including batch processing, streaming, SQL, machine learning, and graph processing. This allows developers to use a single framework for multiple data processing needs.
- Ease of use: Spark provides easy-to-use APIs in Java, Scala, Python, and R. This helps developers and data scientists quickly get started with Spark without needing to learn a new language.
- Scalability: Spark can process data from gigabytes to petabytes on the same computer cluster, allowing applications to scale easily.
- Good integration: Spark can run on Hadoop, Mesos, standalone, or on the cloud. It can also access multiple data sources including HDFS, Cassandra, HBase, and S3.
- Strong community: Spark has a large community of users and developers, ensuring continuous development and support for the framework.
- Real-time processing: With Spark Streaming, organizations can process real-time data, enabling quick decision-making based on the latest information.
- Cost savings: By processing data faster and more efficiently, Spark can help reduce computing and storage costs.

Key Features of Apache Spark
Apache Spark has many outstanding features that make it a powerful data processing tool:
- In-memory processing: Spark uses RAM to store data, increasing processing speed many times compared to disk-based systems.
- Lazy Evaluation: Spark uses lazy evaluation technique, only performing computations when necessary, helping optimize the processing workflow.
- Fault Tolerance: Spark's RDDs have the ability to recover from failures, ensuring stability for big data processing applications.
- Caching: Spark allows caching data in memory, speeding up iterative operations.
- Multi-language support: Supports multiple programming languages including Java, Scala, Python, and R.
- Unified Engine: Spark provides a unified engine for batch processing, streaming, machine learning, and graph processing.
- Query optimization: Spark SQL uses the Catalyst optimizer to optimize SQL queries.
- MLlib: Built-in machine learning library with numerous algorithms and tools.
- GraphX: Graph processing API that enables complex analytics on graph-structured data.
- Rich ecosystem: Spark can integrate with many different tools and data storage systems.

Practical Applications of Apache Spark
Apache Spark is widely used across many different fields for processing and analyzing big data. Below are some practical applications of Spark:
- Big data analytics: Spark is used to process and analyze large datasets in fields such as finance, healthcare, and science.
- Recommendation systems: Companies like Netflix and Amazon use Spark to build product and content recommendation systems for users.
- Fraud detection: Financial institutions use Spark to analyze transactions in real time to detect fraudulent activities.
- Social media analytics: Spark is used to analyze social media data, including sentiment analysis and community detection.
- Internet of Things (IoT): Spark Streaming is used to process data from IoT devices in real time.
- Log analysis: Technology companies use Spark to analyze server and application logs to detect issues and optimize performance.
- Genomics: In the field of biology, Spark is used to process and analyze genomic data.
- Natural language processing: Spark MLlib is used in natural language processing applications such as text classification and sentiment analysis.
- Spatial data analysis: Spark is used to process and analyze satellite and GIS data.
- Optimizing Ad Targeting: Advertising companies use Spark to analyze user behavior and optimize ad targeting.

Advantages and Disadvantages of Apache Spark
Apache Spark is a powerful tool in the field of big data processing, but like any technology, it has its own strengths and weaknesses. Let's examine the outstanding advantages and limitations to note when using Apache Spark:
Advantages
- Fast processing speed: Spark processes data much faster than Hadoop MapReduce thanks to its in-memory processing capability.
- Versatility: Spark supports many different types of data processing tasks within a single framework.
- Ease of use: Intuitive API and support for many popular programming languages.
- Real-time processing: Spark Streaming enables real-time data processing.
- Strong community: Abundant resources, documentation, and community support.
- Good integration: Can integrate with many storage systems and data analytics tools.
- Scalability: Can process from gigabytes to petabytes of data on the same computer cluster.
Disadvantages
- Large memory requirements: To fully leverage Spark's performance, a large amount of RAM is required.
- Initial learning curve: Although easy to use, time is still needed to become familiar with Spark's concepts and APIs.
- Higher latency than dedicated stream processing systems: In some cases, Spark Streaming may have higher latency than dedicated stream processing systems like Apache Flink.
- Not efficient for small tasks: Spark may not be efficient for small data processing tasks due to cluster startup and management overhead.
- Lack of built-in distributed file system: Unlike Hadoop, Spark does not have its own distributed file system and often relies on HDFS or other storage systems.
- Security concerns: Although improved, Spark's security features are still not as robust as some other systems.
- Cost: Powerful hardware requirements, especially RAM, can lead to high deployment costs.

Comparison Between Apache Spark and Apache Hadoop
Apache Spark and Apache Hadoop are two popular frameworks for big data processing, but they have significant differences:
| Criteria | Apache Hadoop | Apache Spark |
|---|---|---|
| Processing model | Uses the MapReduce model, processes data in batch | Uses the Resilient Distributed Datasets (RDD) model, can process both batch and streaming |
| Processing speed | Slower due to reading/writing data from disk | Much faster thanks to in-memory processing |
| Ease of use | More complex, requires more code | More intuitive and easier-to-use API |
| Language support | Primarily supports Java | Supports multiple languages such as Java, Scala, Python, R |
| Machine Learning integration | Requires additional external libraries | Has built-in MLlib |
| Real-time processing | Does not support real-time processing | Has Spark Streaming for real-time processing |
| Resource requirements | Requires fewer resources, can run on standard hardware | Requires more RAM for optimal performance |
| File system | Has built-in HDFS (Hadoop Distributed File System) | No dedicated file system, typically uses HDFS or other storage systems |
| Stability | Has been used for a long time and is very stable | Relatively newer but increasingly stable |
| Use cases | Suitable for batch processing tasks with large data | Suitable for both batch and real-time processing, especially tasks requiring high speed and iterative processing |
What is DNS Sinkhole? Applications and How to Use DNS Sinkhole Techniques
Major Enterprises Using Apache Spark
Many large enterprises around the world have adopted Apache Spark to process and analyze their big data. Below are some notable examples:
- Netflix: Uses Spark to build content recommendation systems and analyze user behavior.
- Uber: Applies Spark to process real-time data from trips and optimize dynamic pricing.
- eBay: Uses Spark to analyze user shopping behavior and improve customer experience.
- NASA: Applies Spark to analyze data from space missions and scientific research.
- Alibaba: Uses Spark to process transaction data and optimize logistics operations.
- LinkedIn: Applies Spark in connection recommendation systems and professional network analytics.
- Yahoo: Uses Spark to analyze user data and improve advertising experience.
- Databricks: A company founded by the creators of Apache Spark, providing a Spark-based platform for enterprises.
- Apple: Applies Spark in internal data analytics systems and improving iCloud services.
- Shopify: Uses Spark to process transaction data and provide insights for store owners.

Frequently Asked Questions About Apache Spark
Why does Spark achieve higher performance when using GPUs?
Spark achieves higher performance when using GPUs (Graphics Processing Units) because:
- Parallel processing: GPUs have thousands of small cores, allowing many computations to be performed simultaneously.
- Optimized for matrix operations: GPUs are designed to efficiently handle matrix operations, which are common in machine learning.
- High memory bandwidth: GPUs have higher memory bandwidth than CPUs, allowing faster data transfer.
- CUDA support: Spark can leverage CUDA, NVIDIA's parallel computing platform, to optimize performance on GPUs.
- ML algorithm acceleration: Many algorithms in Spark MLlib are optimized to run on GPUs.
What programming language is Apache Spark?
Apache Spark is not a programming language but a distributed data processing framework. However, Spark supports multiple programming languages for writing applications:
- Scala: Spark's primary language, providing the most comprehensive API.
- Java: Full support with an API similar to Scala.
- Python: Widely used due to its simplicity and popularity in the data science community.
- R: Supported through SparkR, popular in the statistics community.
Spark provides a unified API for these languages, allowing developers to choose the language that best suits their skills and needs.
{{< test-result title="Comparison of big data processing frameworks" headers="Criteria|Apache Spark|Hadoop MapReduce|Apache Flink|Apache Storm" row1="Processing|In-memory|Disk-based|In-memory|In-memory" row2="Speed|Very fast (100x)|Slow|Fast|Fast" row3="Batch/Stream|Both|Batch only|Both|Stream only" row4="Built-in ML|MLlib|No|FlinkML|No" row5="Languages|Scala, Java, Python, R|Java|Java, Scala|Java, Clojure" />}}
Conclusion: Apache Spark is a powerful big data processing platform with in-memory processing capability, supporting both batch and streaming, with built-in machine learning and graph processing libraries. Used by Netflix, Uber, NASA, and many large enterprises, Spark is an indispensable tool in the field of big data. However, it is important to note the large RAM requirements and high hardware costs when deploying.