









代理是专业网络爬虫不可或缺的工具:避免IP封锁、收集多国数据、将收集速度提升数十倍。本文详细指导如何选择代理、配置代理以及避免爬虫中的常见错误。
什么是网络爬虫?
高速代理 - 准备试用?
ALGO Proxy 提供住宅、数据中心和 4G 代理,覆盖 195+ 国家
想象一下,你需要在50个不同的网站上比较一个产品的价格。手动操作?一整天就没了。这正是网络爬虫诞生的原因。
网络爬虫是从网站自动提取信息的过程。你不需要逐页复制粘贴,只需编写程序,几分钟内就能收集数百万个数据点。如今,网络爬虫被广泛应用于各行各业:
- 电商: 价格比较、竞争对手监控、库存跟踪
- SEO: 关键词排名检查、外链分析
- 市场调研: 产品评论收集、趋势分析
- AI/ML: 为人工智能模型构建训练数据集
- 房地产: 房价跟踪、新楼盘信息
然而,当你从同一个IP发送数百个请求时——网站会检测到并立即封锁你。这时候代理就成了你的秘密武器。
没有代理 vs 有代理:差别一目了然

没有代理的场景:
你从IP 1.2.3.4发送100个请求 → 网站检测到 → 返回403 Forbidden → IP被封禁 → 爬虫项目失败。
有代理的场景:
你通过100个不同的IP发送100个请求 → 每个请求看起来都来自不同用户 → 网站正常响应 → 数据收集成功。
就是这么简单。代理解决了5个核心问题:
- 避免IP封禁 — 在数千个IP之间轮换,每个请求来自不同地址
- 绕过速率限制 — 网站限制60 req/min/IP?用10个IP = 600 req/min
- 多国数据收集 — 美国代理看到美元价格,日本代理看到日元价格
- 保护基础设施 — 你的真实服务器IP永远不会暴露
- 并行加速 — 10个代理同时运行 = 10倍速度
为爬虫选择合适的代理类型
并非所有代理都一样。用错类型 = 白花钱还是被封。
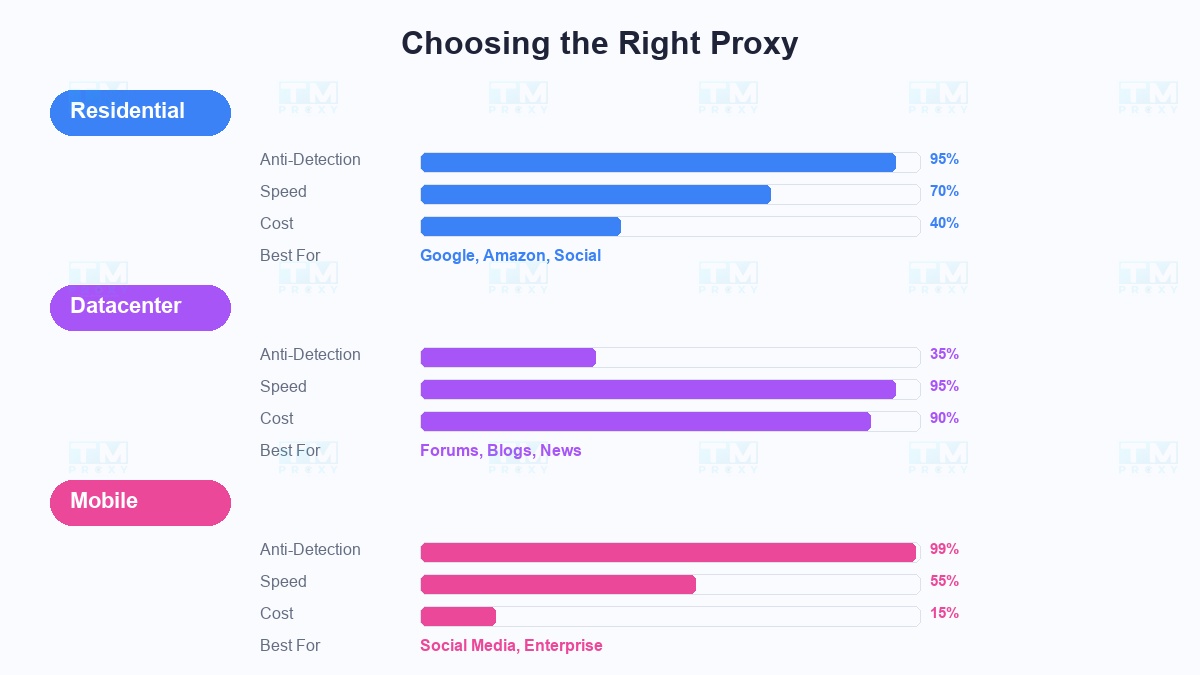
住宅代理 — 反检测之王:
来自ISP的真实IP(Comcast、AT&T、BT...),看起来100%像真实用户。在Google、Amazon、LinkedIn上的成功率高达95%+。不过价格更贵,速度不及数据中心代理。
何时使用: 爬取保护严密的网站(Google、Amazon、社交媒体),需要高成功率的项目。
数据中心代理 — 快速且便宜:
来自数据中心的IP,速度极快,比住宅代理便宜5-10倍。但容易被先进的反机器人系统检测。
何时使用: 爬取小型网站、论坛、博客、新闻站——保护力度低的地方。
移动代理 — 无敌选手:
来自4G/5G网络的IP,与数百万真实用户共享的同类型IP。几乎不可能被检测。但最贵,速度取决于移动网络。
何时使用: 爬取社交媒体、拥有企业级反机器人系统的网站。
| 代理类型 | Google/Amazon | 社交媒体 | 论坛/博客 | 新闻站 | 平均 |
|---|---|---|---|---|---|
| 数据中心 | 32% | 25% | 92% | 88% | 59% |
| 住宅 | 95% | 88% | 98% | 97% | 95% |
| 移动 | 99% | 97% | 99% | 99% | 98% |
住宅代理在大多数数据源上达到95%的平均成功率。数据中心代理仅对保护较弱的论坛和新闻站有效。
高效代理爬虫的步骤
以下是经过实际项目验证的工作流程:
步骤1 — 分析目标网站: 检查robots.txt,了解反机器人机制(Cloudflare、Akamai、PerimeterX?),确定需要收集的数据。
步骤2 — 选择合适的代理类型: 困难网站用住宅代理,简单网站用数据中心代理。先用小批量(100个请求)测试再扩展。
步骤3 — 配置轮换: 每3-5个请求或每30秒更换IP。同一IP永远不要连续使用超过10个请求。
步骤4 — 模拟真实用户行为: 请求之间添加2-8秒的随机延迟。每个会话轮换User-Agent头部。
步骤5 — 智能处理错误: 遇到403 → 立即切换IP。遇到CAPTCHA → 新IP + 增加延迟。遇到429 → 降低速度。
步骤6 — 实时监控: 跟踪成功率。低于90%?有问题需要调整。
步骤7 — 逐步扩展: 从10个并发请求开始,增加到50、100。在每个级别监控成功率。
常见爬虫错误(及如何避免)
经过支持数千客户的经验,以下是最常见的错误:
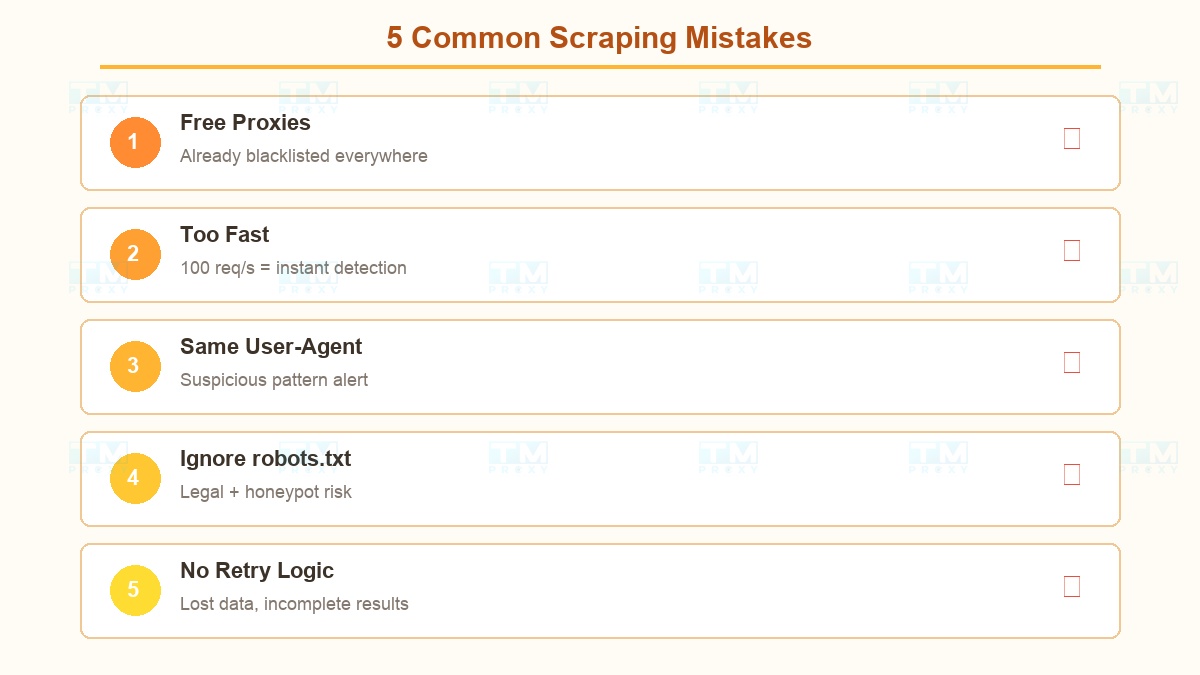
错误#1:使用免费代理 免费代理 = IP早已被到处拉黑。速度慢、不稳定,你的数据还可能被窃取。请投资优质代理。
错误#2:请求发送太快 从相同模式发送100个请求/秒 = 立即被检测。务必添加随机延迟并分散请求。
错误#3:不轮换User-Agent 所有请求相同的User-Agent + 不同IP = 可疑模式。准备至少50个不同User-Agent的列表。
错误#4:忽略robots.txt 除了法律问题,许多反机器人系统会监控你是否访问了robots.txt中禁止的URL。
错误#5:没有重试逻辑 遇到错误直接跳过 → 数据丢失。你需要用新IP + 指数退避的重试机制。
TMProxy爬虫解决方案
大规模数据收集需要可靠的代理基础设施。TMProxy 正是为此而生:
- 数百万IP池 — 覆盖100+国家的住宅和数据中心
- 智能自动轮换 — 根据自定义配置自动切换IP
- HTTP、HTTPS、SOCKS5支持 — 兼容所有爬虫工具
- 监控仪表板 — 实时跟踪使用量、成功率
总结: 没有代理的爬虫就像没有鱼竿的钓鱼。选对代理类型,遵循最佳实践,你就能收集到所有需要的数据而不被封锁。