









Proxy là công cụ không thể thiếu cho web scraping chuyên nghiệp: tránh bị chặn IP, thu thập dữ liệu đa quốc gia, và tăng tốc thu thập lên hàng chục lần. Bài viết hướng dẫn chi tiết cách chọn proxy, cấu hình và tránh sai lầm khi scraping.
Web Scraping là gì?
Proxy tốc độ cao – Sẵn sàng dùng thử?
ALGO Proxy cung cấp proxy residential, datacenter và 4G tại 195+ quốc gia
Hãy tưởng tượng bạn cần so sánh giá của một sản phẩm trên 50 website khác nhau. Làm thủ công? Mất cả ngày. Đó chính là lý do web scraping ra đời.
Web scraping là quá trình tự động trích xuất thông tin từ các trang web bằng phần mềm. Thay vì copy-paste từng trang, bạn viết chương trình để thu thập hàng triệu điểm dữ liệu trong vài phút. Hiện nay, web scraping được ứng dụng rộng rãi:
- E-commerce: So sánh giá, theo dõi đối thủ, monitoring stock
- SEO: Kiểm tra thứ hạng từ khóa, phân tích backlink
- Nghiên cứu thị trường: Thu thập review sản phẩm, phân tích xu hướng
- AI/ML: Xây dựng training dataset cho mô hình trí tuệ nhân tạo
- Bất động sản: Theo dõi giá nhà, thông tin listing mới
Tuy nhiên, khi bạn gửi hàng trăm request từ cùng một IP — website sẽ nhận ra và chặn bạn ngay lập tức. Đây là lúc proxy trở thành vũ khí bí mật.
Không có Proxy vs Có Proxy: Sự khác biệt rõ ràng

Kịch bản KHÔNG có proxy:
Bạn gửi 100 request từ IP 1.2.3.4 → Website phát hiện → Trả về lỗi 403 Forbidden → IP bị ban → Dự án scraping thất bại.
Kịch bản CÓ proxy:
Bạn gửi 100 request qua 100 IP khác nhau → Mỗi request giống như từ một người dùng riêng biệt → Website phản hồi bình thường → Dữ liệu thu thập thành công.
Đơn giản vậy thôi. Proxy giải quyết 5 vấn đề cốt lõi:
- Tránh bị chặn IP — Luân chuyển giữa hàng ngàn IP, mỗi request đến từ địa chỉ khác
- Vượt rate limiting — Website giới hạn 60 req/phút/IP? Dùng 10 IP = 600 req/phút
- Thu thập dữ liệu đa quốc gia — Proxy tại Mỹ thấy giá USD, proxy tại Nhật thấy giá JPY
- Bảo vệ hạ tầng — IP thật của server không bao giờ bị lộ
- Tăng tốc song song — 10 proxy chạy đồng thời = tốc độ gấp 10 lần
Chọn đúng loại Proxy cho Scraping
Không phải proxy nào cũng phù hợp. Dùng sai loại = tốn tiền mà vẫn bị chặn.
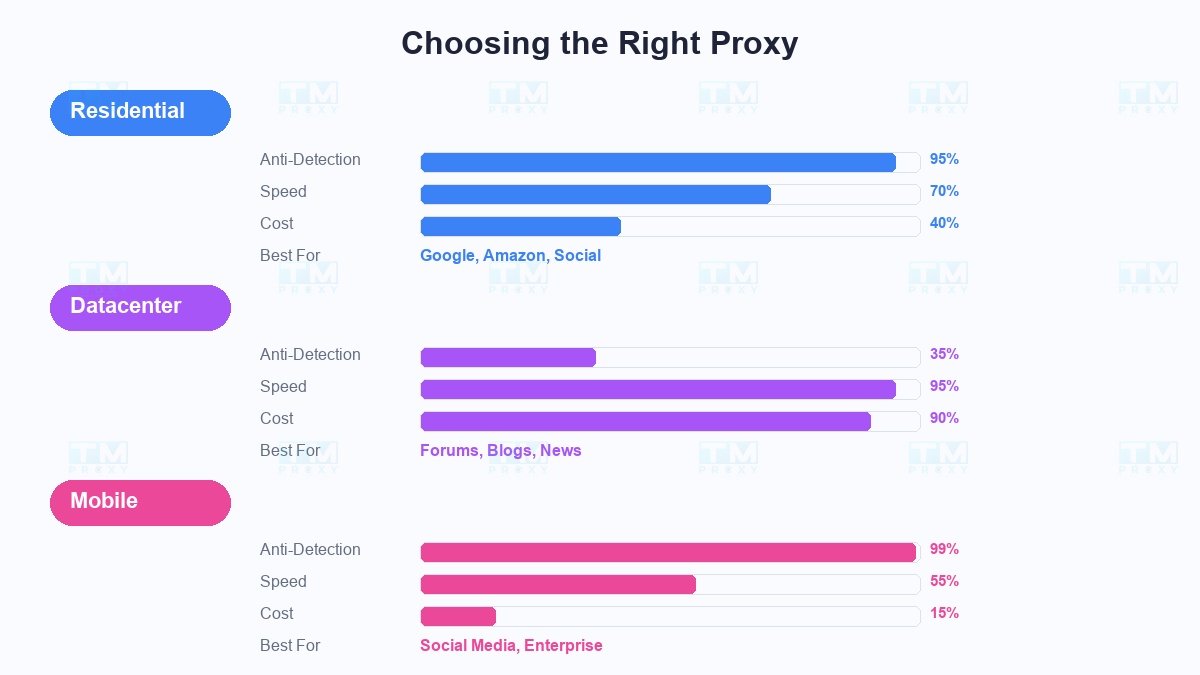
Residential Proxy — Vua của anti-detect:
IP thật từ nhà mạng ISP (Viettel, VNPT, FPT...), trông giống người dùng thật 100%. Tỷ lệ thành công trên Google, Amazon, LinkedIn lên tới 95%+. Tuy nhiên giá cao hơn và tốc độ không bằng datacenter.
Khi nào dùng: Scraping các site bảo vệ chặt (Google, Amazon, mạng xã hội), dự án cần tỷ lệ thành công cao.
Datacenter Proxy — Nhanh và rẻ:
IP từ trung tâm dữ liệu, tốc độ cực nhanh, giá rẻ gấp 5-10 lần residential. Nhưng dễ bị phát hiện bởi hệ thống chống bot tiên tiến.
Khi nào dùng: Scraping website nhỏ, forum, blog, trang tin tức — những nơi ít bảo vệ.
Mobile Proxy — Bất khả chiến bại:
IP từ mạng 4G/5G, cùng loại IP mà hàng triệu người dùng thật chia sẻ. Gần như không thể bị phát hiện. Nhưng giá đắt nhất và tốc độ phụ thuộc mạng di động.
Khi nào dùng: Scraping mạng xã hội, trang có hệ thống chống bot cấp enterprise.
| Loại Proxy | Google/Amazon | Social Media | Forum/Blog | Trang tin | Trung bình |
|---|---|---|---|---|---|
| Datacenter | 32% | 25% | 92% | 88% | 59% |
| Residential | 95% | 88% | 98% | 97% | 95% |
| Mobile | 99% | 97% | 99% | 99% | 98% |
Residential proxy đạt tỷ lệ thành công trung bình 95% trên hầu hết nguồn dữ liệu. Datacenter proxy chỉ hiệu quả với forum và trang tin ít bảo vệ.
Scraping hiệu quả với Proxy
Đây là quy trình đã được kiểm chứng qua nhiều dự án thực tế:
Bước 1 — Phân tích target website: Kiểm tra robots.txt, tìm hiểu cơ chế chống bot (Cloudflare, Akamai, PerimeterX?), xác định data cần thu thập.
Bước 2 — Chọn loại proxy phù hợp: Residential cho site khó, datacenter cho site dễ. Bắt đầu test với batch nhỏ (100 request) trước khi scale.
Bước 3 — Cấu hình rotation: Thay đổi IP sau mỗi 3-5 request hoặc sau mỗi 30 giây. Không bao giờ dùng cùng IP quá 10 request liên tiếp.
Bước 4 — Giả lập hành vi người thật: Thêm delay ngẫu nhiên 2-8 giây giữa các request. Xoay User-Agent header theo từng session.
Bước 5 — Xử lý lỗi thông minh: Gặp 403 → đổi IP ngay. Gặp CAPTCHA → chuyển sang IP mới + tăng delay. Gặp 429 → giảm tốc độ.
Bước 6 — Giám sát real-time: Theo dõi tỷ lệ thành công. Dưới 90%? Có vấn đề cần điều chỉnh.
Bước 7 — Scale dần dần: Bắt đầu từ 10 concurrent request, tăng dần lên 50, 100. Theo dõi tỷ lệ thành công ở mỗi mức.
Sai lầm phổ biến khi Scraping (và cách tránh)
Qua kinh nghiệm hỗ trợ hàng ngàn khách hàng, đây là những lỗi thường gặp nhất:
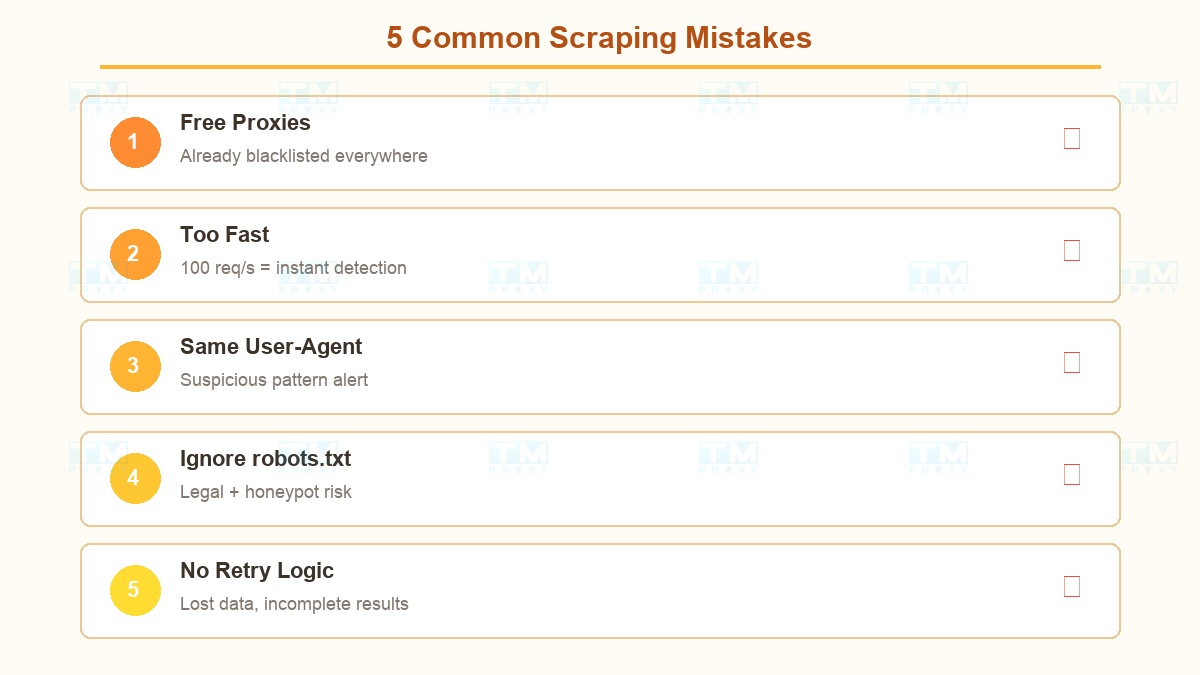
Sai lầm #1: Dùng proxy miễn phí Proxy free = IP đã bị blacklist ở khắp nơi. Tốc độ chậm, không ổn định, và có thể bị đánh cắp dữ liệu. Hãy đầu tư vào proxy chất lượng.
Sai lầm #2: Gửi request quá nhanh 100 request/giây từ cùng pattern = bị phát hiện ngay. Luôn thêm random delay và phân tán request.
Sai lầm #3: Không xoay User-Agent Mọi request cùng User-Agent + khác IP = pattern đáng ngờ. Chuẩn bị danh sách ít nhất 50 User-Agent khác nhau.
Sai lầm #4: Bỏ qua robots.txt Ngoài vấn đề pháp lý, nhiều anti-bot system giám sát xem bạn có truy cập các URL bị cấm trong robots.txt không.
Sai lầm #5: Không có retry logic Khi gặp lỗi mà chỉ skip → mất dữ liệu. Cần có cơ chế retry với IP mới + exponential backoff.
Giải pháp Proxy Scraping từ TMProxy
Thu thập dữ liệu quy mô lớn đòi hỏi hạ tầng proxy đáng tin cậy. TMProxy được thiết kế riêng cho nhu cầu này:
- Pool hàng triệu IP residential và datacenter tại 100+ quốc gia
- Auto-rotation thông minh — tự đổi IP theo cấu hình tùy chỉnh
- Hỗ trợ HTTP, HTTPS, SOCKS5 — phù hợp mọi tool scraping
- Dashboard giám sát — theo dõi usage, success rate real-time
Kết luận: Scraping không có proxy giống như đi câu cá mà không có cần. Chọn đúng loại proxy, tuân thủ best practices, và bạn sẽ thu thập được mọi dữ liệu cần thiết mà không bị chặn.